Introdução ao Snowflake Open Catalog¶
Visão geral¶
O Snowflake Open Catalog é um catálogo aberto para o Apache Iceberg™. O Open Catalog está disponível como um serviço SaaS gerenciado no Snowflake. Ele também está disponível como código-fonte aberto que você pode criar e implementar. O Open Catalog fornece uma implementação do catálogo Apache Iceberg REST com segurança entre mecanismos por meio de controle de acesso baseado em função.
Neste tutorial, você aprenderá como começar a usar o Open Catalog gerenciado no Snowflake.
O que você aprenderá¶
Como criar uma nova conta no Open Catalog.
Como criar um novo catálogo Iceberg na conta do Open Catalog e protegê-lo usando RBAC.
Como usar o Apache Spark™ para criar tabelas no catálogo e executar consultas.
Como usar o Snowflake para executar consultas em tabelas no catálogo.
Como espelhar ou publicar tabelas Iceberg gerenciadas no Snowflake para o Open Catalog.
O que você vai precisar¶
Privilégios ORGADMIN em sua organização Snowflake (para criar uma nova conta do Open Catalog).
Privilégios ACCOUNTADMIN em sua conta Snowflake (para conectar-se à conta Open Catalog). Esta conta Snowflake não precisa ser a mesma que a conta da organização Snowflake.
O que você vai fazer¶
Você concluirá dois casos de uso:
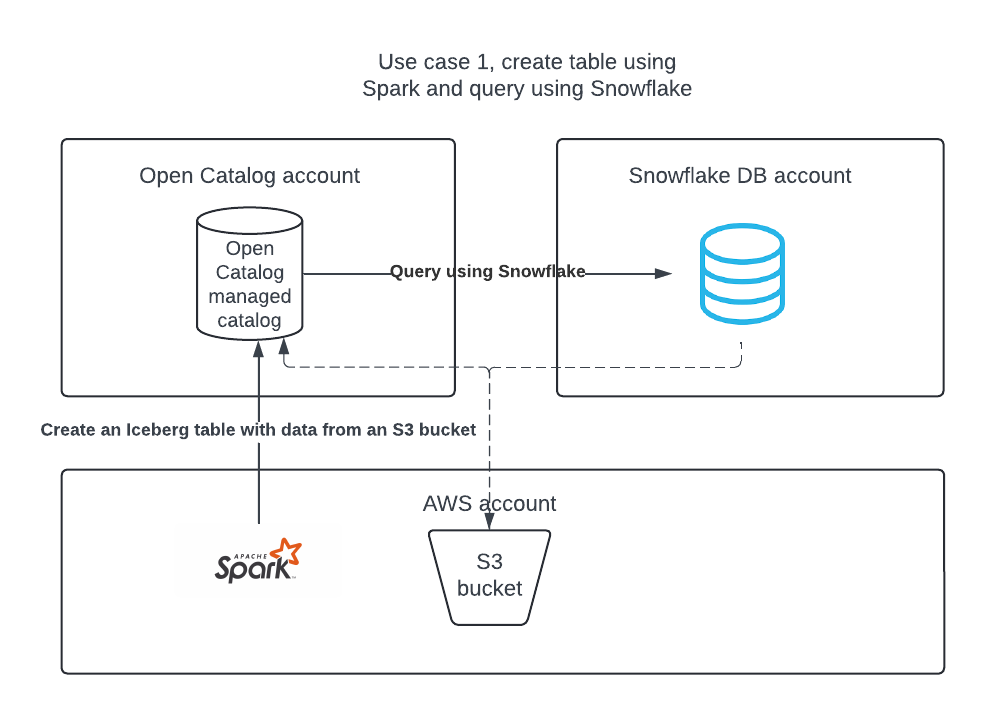
Caso de uso 1: Crie um catálogo no Open Catalog, crie uma tabela usando o Apache Spark e consulte a tabela usando o Apache Spark e o Snowflake.
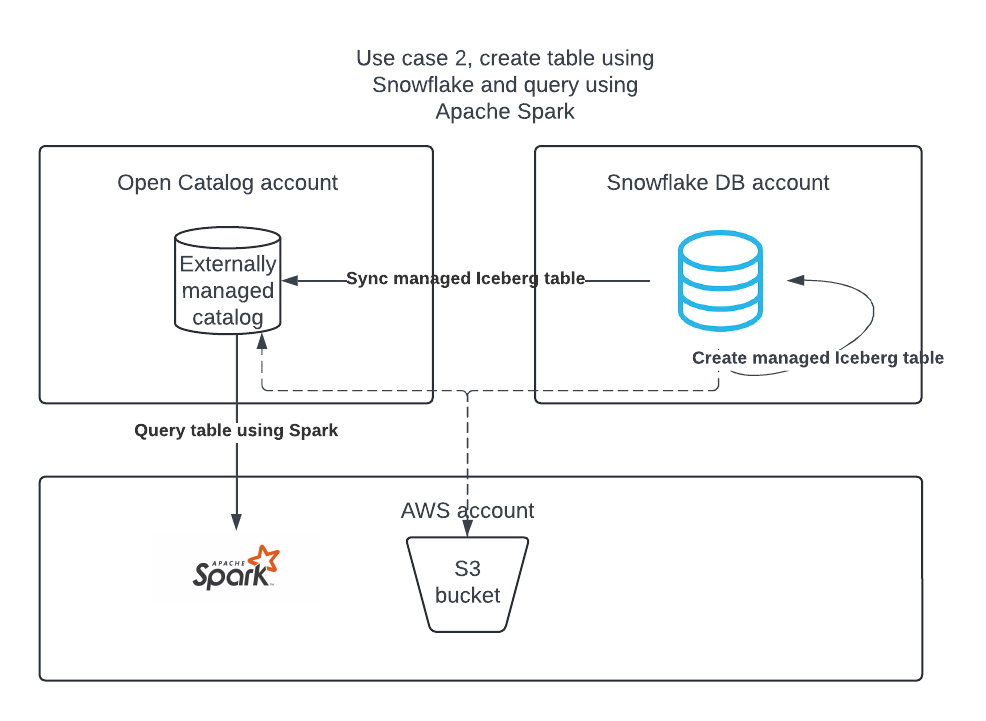
Caso de uso 2: Crie uma tabela Apache Iceberg na conta Snowflake DB usando o Snowflake e publique-a no Open Catalog para que o Apache Spark possa executar consultas nela.
Configuração do ambiente¶
Instale Conda, Spark e Jupyter em seu laptop¶
Neste tutorial, é possível usar o Conda para criar facilmente um ambiente de desenvolvimento e baixar os pacotes necessários. Isso só será necessário se você seguir o caso de uso 2 para usar o Apache Spark™ para ler tabelas do Apache Iceberg™ gerenciadas pelo Snowflake. Isso não é necessário para criar ou usar tabelas Iceberg no Snowflake.
Para instalar o Conda, use as instruções específicas para o seu OS:
Crie um arquivo chamado
environment.ymlcom o seguinte conteúdo:name: iceberg-lab channels: - conda-forge dependencies: - findspark=2.0.1 - jupyter=1.0.0 - pyspark=3.5.0 - openjdk=11.0.13
Para criar o ambiente necessário, execute o seguinte em seu shell:
conda env create -f environment.yml
Crie uma conta Open Catalog¶
Uma conta Open Catalog pode ser criada somente por um ORGADMIN.
No Snowsight, no painel de navegação, selecione Admin > Contas.
No menu suspenso + Conta, selecione Criar conta do Snowflake Open Catalog.
Conclua a caixa de diálogo Criar conta do Snowflake Open Catalog:
Nuvem: O provedor de nuvem onde deseja armazenar tabelas Apache Iceberg™.
Região: A região onde deseja armazenar as tabelas Iceberg.
Edição: A edição para sua conta Open Catalog.
Selecione Avançar.
Na caixa de diálogo Criar nova conta, preencha os campos Nome da conta, Nome de usuário, Senha e E-mail.
Selecione Criar conta. Sua nova conta do Open Catalog será criada e uma caixa de confirmação será exibida.
Na caixa de confirmação, selecione URL do localizador de contas para abrir o URL do localizador de contas em seu navegador da Web.
Adicione o URL do localizador de contas aos favoritos. Ao fazer login no Open Catalog, você deve especificar o URL do localizador de conta.
Faça login na interface da Web do Open Catalog¶
Clique no URL da conta que você recebeu por e-mail após criar a conta, OR vá para https://app.snowflake.com.
Clique em Fazer login em uma conta diferente e faça login com a conta do Open Catalog criada anteriormente.
Caso de uso 1: Crie uma tabela usando o Apache Spark™¶
Criação de um IAM política que conceda acesso ao seu local S3¶
Se você ainda não tiver uma, comece criando uma política de IAM que conceda acesso ao local de seu S3. Para obter instruções sobre como criar esta política, consulte Criação de uma política de IAM que concede acesso ao local de seu S3.
Crie uma função IAM¶
Se você ainda não tiver uma, crie uma função AWS IAM para o Open Catalog para conceder privilégios em seu bucket S3. Para obter instruções, consulte Criação de uma função IAM. Quando as instruções solicitarem que você selecione uma política, selecione a política de IAM que concede acesso ao local de seu S3.
Criação de um catálogo interno no Open Catalog¶
É possível usar um catálogo interno em sua conta do Open Catalog para criar tabelas, consultá-las e executar DML nelas usando o Apache Spark™ ou outros mecanismos de consulta.
Entre em sua nova conta do Open Catalog.
Para criar um novo catálogo, no painel à esquerda, selecione Catálogos.
Selecione + Catálogo no canto superior direito.
Na caixa de diálogo Criar catálogo, insira os seguintes detalhes:
Nome: nomear o catálogo demo_catalog.
Local base padrão: O local onde os dados da tabela serão armazenados.
Locais adicionais (opcional): Uma lista separada por vírgulas de vários locais de armazenamento. Ele é usado principalmente se você precisar importar tabelas de diferentes locais neste catálogo. Você pode deixar em branco.
ARN da função S3: Uma função AWS que tem acesso de leitura e gravação aos locais de armazenamento. Insira o ARN do nome da função de IAM que você criou para o Open Catalog.
ID externo: (opcional): Um segredo que você deseja fornecer ao criar uma relação de confiança entre o usuário do catálogo e a conta de armazenamento. Se você ignorar isso, ele será gerado automaticamente. Use uma cadeia de caracteres simples como abc123 para este tutorial.
Selecione Criar. Seu catálogo é criado e os seguintes valores são adicionados a ele:
O ARN do usuário de IAM para sua conta do Open Catalog.
Se você não inseriu um ID externo, um ID externo será gerado automaticamente para seu catálogo.
Você precisará desses valores na próxima seção ao criar uma relação de confiança.
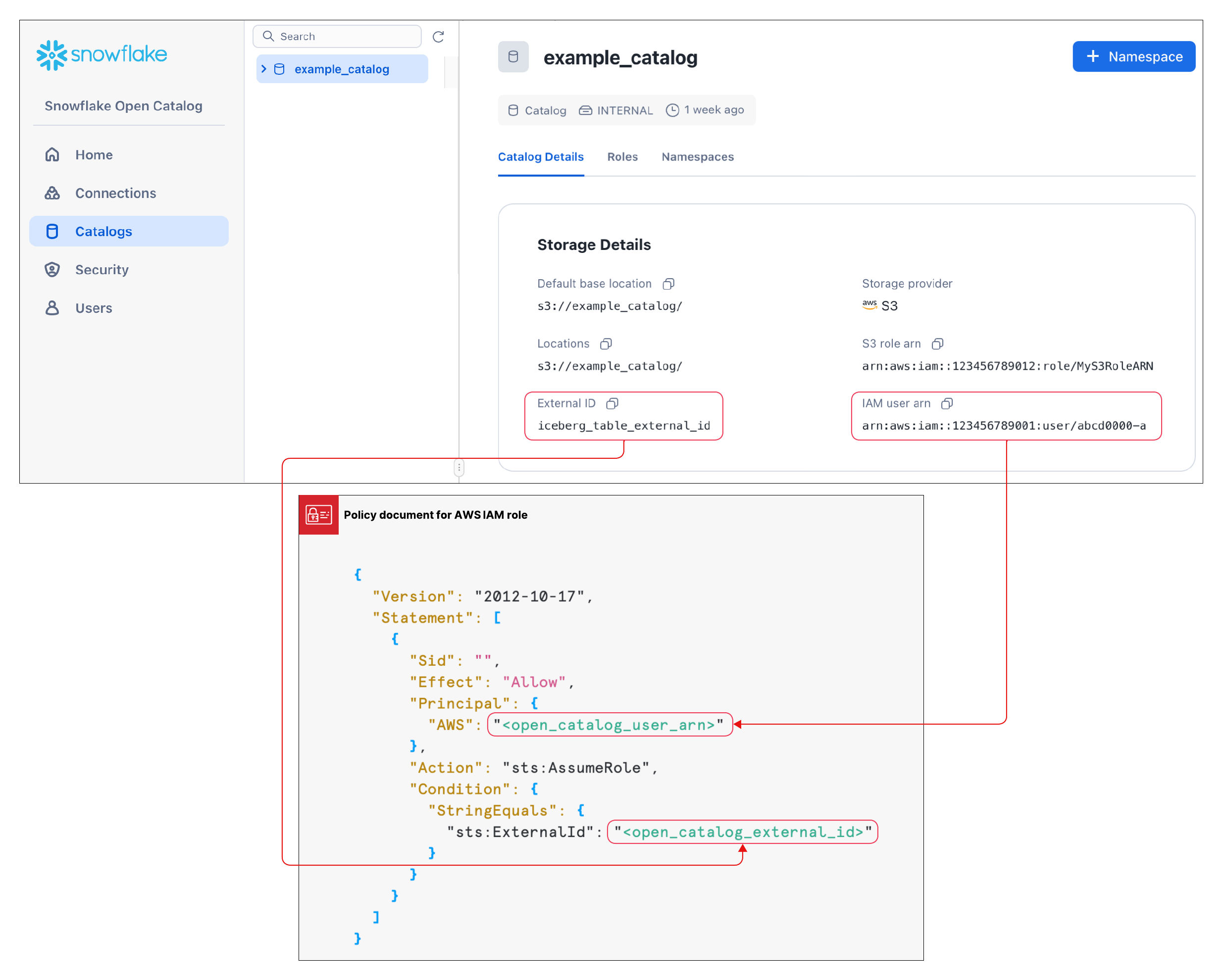
Crie uma relação de confiança¶
Após criar um catálogo, você precisa definir uma relação de confiança para que a função S3 especificada na configuração acima possa ler e gravar dados no local de armazenamento. Observe que para concluir esta tarefa, você precisará do ARN do usuário de S3 IAM e o ID externo para seu catálogo.
Após a criação do catálogo, selecione-o na lista para exibir o ARN do usuário de S3 IAM e o ID externo de seu catálogo.
Para criar a relação de confiança, conclua as instruções em Etapa 5: conceda ao usuário de IAM permissões para acessar objetos do bucket.
No objeto JSON mostrado nestas instruções:
Em
<open_catalog_user_arn>, use o valor em ARN do usuário de IAM na UI do Open Catalog.Em
<open_catalog_external_id>, use o valor em ID externo na UI do Open Catalog.
Configure uma nova conexão de serviço para o Apache Spark™¶
Crie uma nova conexão (par client_id/client_secret) para o Apache Spark executar consultas no catálogo que você acabou de criar.
No Open Catalog, no painel esquerdo, selecione a guia Conexões e, em seguida, selecione + Conexão no canto superior direito.
Na caixa de diálogo Configurar conexão de serviço, crie uma nova função de entidade ou escolha uma das funções disponíveis.
Selecione Criar.
Na caixa de diálogo Configurar conexão de serviço, para copiar o ID do cliente e o segredo do cliente para um editor de texto, selecione Copiar dentro do campo Como <CLIENT ID>:<SECRET>
Importante
Você não poderá recuperar essas cadeias de caracteres de texto do serviço Open Catalog mais tarde, portanto, você deve copiá-las agora. Use essas cadeias de caracteres de texto ao configurar o Spark.
Definição dos privilégios de catálogo para conexão¶
Agora você concede privilégios à conexão de serviço para que ela possa acessar o catálogo. Sem privilégios de acesso, a conexão de serviço não pode executar nenhuma consulta no catálogo.
No painel de navegação, selecione Catálogos e, em seguida, selecione seu catálogo na lista.
Para criar uma nova função, selecione a guia Funções.
Selecione + Função de catálogo.
Na caixa de diálogo Criar função de catálogo, para Nome, insira spark_catalog_role.
Em Privilégios, selecione CATALOG_MANAGE_CONTENT e depois selecione Criar.
Isso dá à função privilégios para criar, ler e gravar em tabelas.
Selecione Conceder à função de entidade.
Na caixa de diálogo Função do catálogo de concessões, para Função de entidade receber concessão, selecione my_spark_admin_role.
Em Função de catálogo a ser concedida, selecione spark_catalog_role e, em seguida, selecione Conceder.
Como resultado desse procedimento, a função spark_catalog_role é concedida a my_spark_admin_role, o que concede privilégios de administrador para a conexão Spark que você criou no procedimento anterior.
Instalação do Spark¶
Em seu terminal, execute os seguintes comandos para ativar o ambiente virtual que você criou na configuração e abrir os notebooks Jupyter:
conda activate iceberg-lab
jupyter notebook
Configuração do Spark¶
Para registrar a conexão de serviço, execute os seguintes comandos em um notebook Jupyter.
import os os.environ['SPARK_HOME'] = '/Users/<username>/opt/anaconda3/envs/iceberg-lab/lib/python3.12/site-packages/pyspark' import pyspark from pyspark.sql import SparkSession spark = SparkSession.builder.appName('iceberg_lab') \ .config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \ .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \ .config('spark.sql.defaultCatalog', 'opencatalog') \ .config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \ .config('spark.sql.catalog.opencatalog.type', 'rest') \ .config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \ .config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \ .config('spark.sql.catalog.opencatalog.credential','<client_id>:<client_secret>') \ .config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \ .config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \ .getOrCreate() #Show namespaces spark.sql("show namespaces").show() #Create namespace spark.sql("create namespace spark_demo") #Use namespace spark.sql("use namespace spark_demo") #Show tables; this will show no tables since it is a new namespace spark.sql("show tables").show() #create a test table spark.sql("create table test_table (col1 int) using iceberg"); #insert a record in the table spark.sql("insert into test_table values (1)"); #query the table spark.sql("select * from test_table").show();
Para obter mais informações, consulte Registrar uma conexão de serviço no Spark.
Parâmetros¶
Parâmetro |
Descrição |
|---|---|
|
Especifica o nome do catálogo ao qual se conectar. |
|
Especifica a coordenada Maven para seu provedor de armazenamento em nuvem externo:
|
|
Especifica o ID de cliente a ser usado pela entidade de serviço. |
|
Especifica o segredo de cliente a ser usado pela entidade de serviço. |
|
Especifica o identificador de conta para sua conta do Open Catalog. |
|
Especifica a função principal concedida ao principal de serviço. |
Opcional: S3 entre regiões¶
Quando sua conta do Open Catalog estiver hospedada no Amazon S3, mas estiver localizada em uma região diferente da região em que seu bucket de armazenamento S3 está localizado, você deverá fornecer uma definição adicional de configuração do Spark:
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
<target_s3_region> especifica a região em que seu bucket de armazenamento S3 está localizado. Para obter a lista de códigos de região, consulte Pontos de extremidade regionais na documentação do AWS.
O exemplo de código a seguir é modificado para incluir a região S3:
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('iceberg_lab') \
.config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', 'opencatalog') \
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.opencatalog.type', 'rest') \
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \
.config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \
.config('spark.sql.catalog.opencatalog.credential','<client_id>:<secret>') \
.config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \
.config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
.getOrCreate()
Consulta às tabelas usando o Snowflake¶
Você pode criar um objeto de integração de catálogo no Snowflake e criar uma tabela Apache Iceberg™ no Snowflake que represente a tabela no Open Catalog. No exemplo a seguir, você cria uma tabela Iceberg no Snowflake que representa a tabela Iceberg recém-criada pelo Spark no catálogo interno do Open Catalog.
É possível usar as mesmas credenciais de conexão do Spark ou criar uma nova conexão do Snowflake. Se você criar uma nova conexão, precisará definir funções e privilégios adequadamente.
Crie um objeto de integração de catálogo:
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_int CATALOG_SOURCE = POLARIS TABLE_FORMAT = ICEBERG CATALOG_NAMESPACE = '<catalog_namespace>' REST_CONFIG = ( CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog' CATALOG_NAME = ‘<catalog_name>’ ) REST_AUTHENTICATION = ( TYPE = OAUTH OAUTH_CLIENT_ID = '<client_id>' OAUTH_CLIENT_SECRET = '<secret>' OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL') ) ENABLED = TRUE; # the <catalog_namespace> created in previous step is spark_demo. # the <catalog_name> created in previous step is demo_catalog.
Crie a representação da tabela no Snowflake usando a integração de catálogo criada acima e consulte a tabela:
CREATE OR REPLACE ICEBERG TABLE test_table CATALOG = 'demo_open_catalog_int' EXTERNAL_VOLUME = '<external_volume>' CATALOG_TABLE_NAME = 'test_table'; SELECT * FROM test_table;
Caso de uso 2: Sincronize tabelas Apache Iceberg™ do Snowflake para o Open Catalog¶
Se você tiver tabelas Iceberg no Snowflake, poderá sincronizá-las com o Open Catalog para que outros mecanismos possam consultá-las.
Criação de um catálogo externo no Open Catalog¶
As tabelas Iceberg do Snowflake podem ser sincronizadas em um catálogo externo em sua conta do Open Catalog.
Entre em sua nova conta do Open Catalog.
Para criar um novo catálogo, no painel à esquerda, selecione Catálogos.
Selecione + Catálogo no canto superior direito.
Na caixa de diálogo Criar catálogo, insira os seguintes detalhes:
Nome: Nomeie o catálogo como demo_catalog_ext.
Defina o seletor de Externo como Ativado.
Local base padrão: O local onde os dados da tabela serão armazenados.
Observação
É necessário usar um local de armazenamento diferente do catálogo interno criado durante o Caso de uso 1 deste tutorial. Para garantir que os privilégios de acesso definidos para um catálogo sejam aplicados corretamente, dois catálogos diferentes não podem ter locais sobrepostos.
Locais adicionais (opcional): Uma lista separada por vírgulas de vários locais de armazenamento. Ele é usado principalmente se você precisar importar tabelas de diferentes locais neste catálogo. Você pode deixar em branco.
ARN da função S3: Uma função AWS que tem acesso de leitura e gravação aos locais de armazenamento.
ID externo: (opcional): Um segredo que você deseja fornecer ao criar uma relação de confiança entre o usuário do catálogo e a conta de armazenamento. Se você ignorar isso, ele será gerado automaticamente. Use uma cadeia de caracteres simples como abc123 para este tutorial.
Selecione Criar. Os seguintes valores são adicionados ao seu catálogo:
O ARN do usuário de IAM para sua conta do Open Catalog.
Se você não inseriu um ID externo, um ID externo será gerado automaticamente para seu catálogo.
Configurar uma nova conexão de serviço para o Snowflake¶
No Open Catalog, no painel esquerdo, selecione a guia Conexões e, em seguida, selecione + Conexão no canto superior direito.
Na caixa de diálogo Configurar conexão de serviço, crie uma nova função de entidade ou escolha uma das funções disponíveis.
Selecione Criar.
Na caixa de diálogo Configurar conexão de serviço, para copiar o ID do cliente e o segredo do cliente para um editor de texto, selecione Copiar dentro do campo Como <CLIENT ID>:<SECRET>
Importante
Você não poderá recuperar essas cadeias de caracteres de texto do serviço Open Catalog mais tarde, portanto, você deve copiá-las agora. Use essas cadeias de caracteres de texto ao configurar o Spark.
Definição de privilégios de catálogo¶
Para definir privilégios no catálogo externo para que a conexão Snowflake tenha os privilégios corretos para um catálogo externo, siga estas etapas:
No painel de navegação, selecione Catálogos e, em seguida, selecione seu catálogo externo na lista.
Para criar uma nova função, selecione a guia Funções.
Selecione + Função de catálogo.
Na caixa de diálogo Criar função de catálogo, para Nome, insira spark_catalog_role.
Em Privilégios, selecione CATALOG_MANAGE_CONTENT e depois selecione Criar.
Isso dá à função privilégios para criar, ler e gravar em tabelas.
Selecione Conceder à função de entidade.
Na caixa de diálogo Função do catálogo de concessões, para Função de entidade receber concessão, selecione my_spark_admin_role.
Em Função de catálogo a ser concedida, selecione spark_catalog_role e, em seguida, selecione Conceder.
Criação de um objeto de integração de catálogo no Snowflake¶
No Snowflake, crie um objeto de integração de catálogo usando o comandoCREATE CATALOG INTEGRATION (Snowflake Open Catalog). Para CATALOG_NAME, especifique o nome do catálogo externo que configurou na sua conta do Open Catalog (demo_catalog_ext).
O Snowflake sincroniza a tabela e seu namespace pai com esse catálogo externo no Open Catalog. Por exemplo, se tiver uma tabela open_catalog_demo.iceberg.test_table_managed Iceberg registrada no Snowflake e especificar demo_catalog_ext na integração do catálogo, o Snowflake sincronizará a tabela com o Open Catalog com o seguinte nome totalmente qualificado: demo_catalog_ext.open_catalog_demo.iceberg.test_table_managed.
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_ext
CATALOG_SOURCE=POLARIS
TABLE_FORMAT=ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog'
CATALOG_NAME = '<catalog_name>'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<client_id>'
OAUTH_CLIENT_SECRET = '<secret>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED=TRUE;
# the <catalog_name> created in previous step is demo_catalog_ext.
Configurar a sincronização do catálogo¶
Antes de poder sincronizar uma tabela Iceberg gerenciada pelo Snowflake com o Open Catalog, especifique o catálogo externo no Open Catalog com o qual o Snowflake deve sincronizar a tabela.
Para configurar a sincronização do catálogo, use o comando ALTER DATABASE com o parâmetro CATALOG_SYNC. Para o valor desse parâmetro, especifique o nome da integração do catálogo para o Open Catalog. Por exemplo:
ALTER DATABASE open_catalog_demo SET CATALOG_SYNC = 'demo_open_catalog_ext';
Depois de executar esse código, o Snowflake sincroniza todas as tabelas Iceberg gerenciadas pelo Snowflake no banco de dados open_catalog_demo com o catálogo externo <catalog_name> no Open Catalog que você especificou na integração do catálogo demo_open_catalog_ext.
Criar uma tabela Iceberg gerenciada pelo Snowflake¶
Crie uma tabela Iceberg gerenciada pelo Snowflake e sincronize-a do Snowflake com o Open Catalog. Para obter mais informações, consulte:
Importante
O
STORAGE_BASE_URLpara o volume externo deve corresponder ao local base padrão do catálogo externo criado no Open Catalog.
use database open_catalog_demo;
use schema iceberg;
# Note that the storage location for this external volume will be different than the storage location for the external volume in use case 1
CREATE OR REPLACE EXTERNAL VOLUME snowflake_demo_ext
STORAGE_LOCATIONS =
(
(
NAME = '<storage_location_name>'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://<s3_location>'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<aws_acct>:role/<rolename>'
STORAGE_AWS_EXTERNAL_ID = '<external_id>'
)
);
CREATE OR REPLACE ICEBERG TABLE test_table_managed (col1 int)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'snowflake_demo_ext'
BASE_LOCATION = 'test_table_managed'
Quando você modifica a tabela no Snowflake, as alterações são sincronizadas automaticamente com o catálogo externo na sua conta Open Catalog. Outros mecanismos, como o Apache Spark™, podem consultar a tabela conectando-se ao Open Catalog.
Observação
Se a tabela não sincronizar com o Open Catalog, execute a função de sistema SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG para diagnosticar o motivo da falha de sincronização. Para obter mais informações, consulte SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG.
Conclusão¶
É possível usar um catálogo interno em sua conta do Open Catalog para criar tabelas, consultá-las e executar operações DML nessas tabelas usando o Apache Spark™ ou outros mecanismos de consulta.
No Snowflake, é possível criar uma integração de catálogo para o Open Catalog para executar as seguintes tarefas:
Execute consultas em tabelas gerenciadas pelo Open Catalog.
Sincronize as tabelas do Snowflake com um catálogo externo em sua conta do Open Catalog.
O que você aprendeu¶
Crie uma conta no Open Catalog.
Crie um catálogo interno em sua conta do Open Catalog.
Use o Spark para criar tabelas no catálogo interno.
Use o Snowflake para criar uma integração de catálogo para o Open Catalog para executar consultas em uma tabela criada em um catálogo interno em sua conta do Open Catalog.
Crie um catálogo externo em sua conta do Open Catalog.
Crie uma tabela gerenciada do Apache Iceberg™; no Snowflake e sincronize-a, juntamente com dois namespaces pai, com o catálogo externo em sua conta do Open Catalog. No tutorial, você aprendeu a configurar a sincronização do catálogo no nível do banco de dados. No entanto, você também pode configurá-lo no nível da conta, do esquema ou da tabela e sincronizá-lo com um namespace pai. Para obter mais informações, consulte os seguintes tópicos:
Para obter um exemplo de configuração da sincronização do catálogo no nível do esquema, consulte Configurar a sincronização do catálogo no nível do esquema na documentação do Snowflake.
Para obter mais informações sobre como configurar a sincronização do catálogo, consulte CATALOG_SYNC na documentação do Snowflake.
Para sincronizar a tabela com um namespace pai, defina a propriedade CATALOG_SYNC_NAMESPACE_MODE com o comando CREATE DATABASE. Para saber mais, consulte CREATE DATABASE na documentação do Snowflake.
Nota
Se o mecanismo de consulta de terceiros só puder consultar tabelas localizadas até o segundo nível de namespace em um catálogo, você deverá sincronizar a tabela com um namespace pai. Caso contrário, o Snowflake sincronizará a tabela com o terceiro nível de namespace no Open Catalog e você não poderá consultar a tabela.