Snowflake Open Catalog 시작하기¶
개요¶
Snowflake Open Catalog는 Apache Iceberg™용 공개 카탈로그입니다. Open Catalog는 Snowflake에서 관리되는 SaaS 서비스로 제공됩니다. 또한 사용자가 직접 빌드하고 배포할 수 있는 오픈 소스 코드로도 제공됩니다. Open Catalog는 역할 기반 액세스 제어를 통해 교차 엔진 보안을 갖춘 Apache Iceberg REST 카탈로그의 구현을 제공합니다.
이 자습서에서는 Snowflake에서 관리되는 Open Catalog를 시작하는 방법을 알아봅니다.
알아볼 내용¶
새로운 Open Catalog 계정을 만드는 방법.
Open Catalog 계정에서 새로운 Iceberg 카탈로그를 만들고 RBAC를 사용하여 보안을 유지하는 방법.
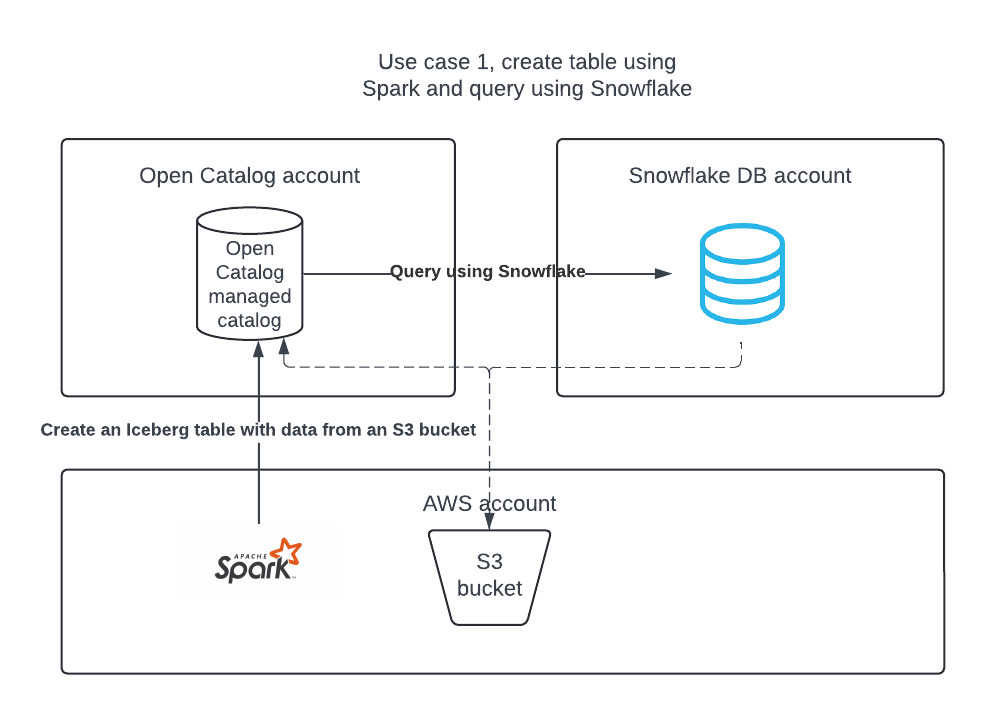
Apache Spark™를 사용하여 카탈로그에 테이블을 만들고 쿼리를 실행하는 방법.
Snowflake를 사용하여 카탈로그의 테이블에서 쿼리를 실행하는 방법.
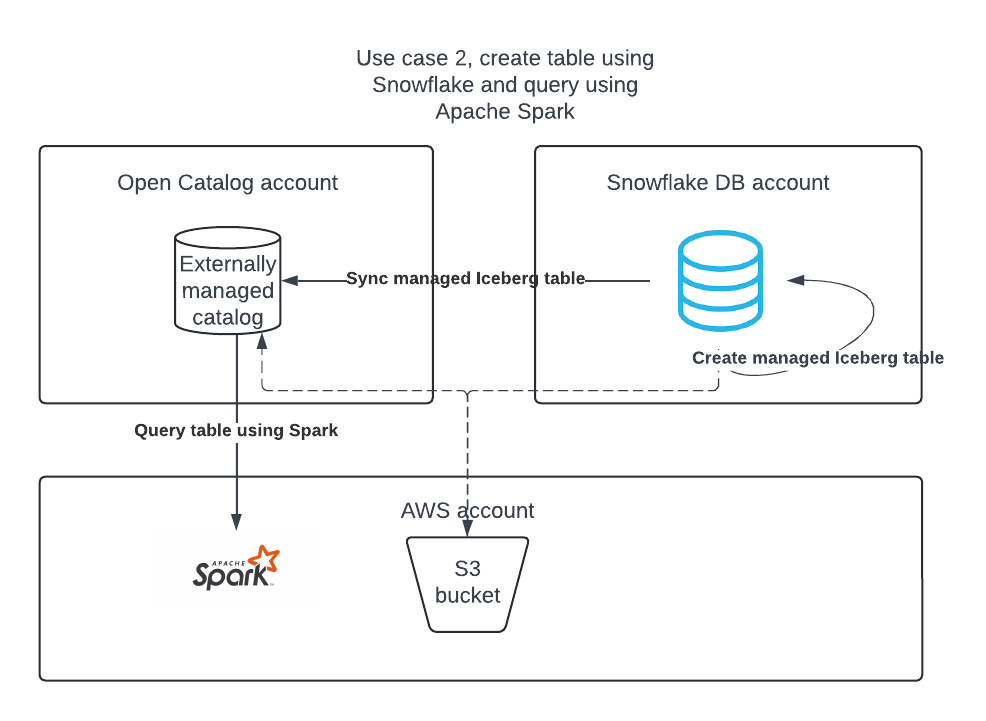
Snowflake에서 관리되는 Iceberg 테이블을 Open Catalog에 미러링하거나 게시하는 방법.
필요한 사항¶
(새로운 Open Catalog 계정을 생성하기 위한) Snowflake 조직에서의 ORGADMIN 권한.
(Open Catalog 계정에 연결하기 위한) Snowflake 계정에서의 ACCOUNTADMIN 권한. 이 Snowflake 계정이 Snowflake 조직 계정과 동일할 필요는 없습니다.
해야 할 일¶
다음 두 가지 사용 사례를 완료해볼 예정입니다.
사용 사례 1: Open Catalog에서 카탈로그를 만들고, Apache Spark를 사용하여 테이블을 만들고, Apache Spark와 Snowflake를 사용하여 테이블을 쿼리합니다.
사용 사례 2: Snowflake를 사용하여 Snowflake DB 계정에서 Apache Iceberg 테이블을 만들고, 이를 Open Catalog에 게시하여 Apache Spark가 테이블에서 쿼리를 실행할 수 있도록 합니다.
환경 설정¶
노트북에 Conda, Spark, Jupyter 설치하기¶
이 자습서에서는 Conda를 사용하여 손쉽게 개발 환경을 만들고 필요한 패키지를 다운로드할 수 있습니다. 이 작업은 Apache Spark™를 사용하여 Snowflake가 관리하는 Apache Iceberg™ 테이블을 읽는 사용 사례 2를 따르는 경우에만 필요합니다. 이는 Snowflake에서 Iceberg 테이블을 만들거나 사용하는 데는 필요하지 않습니다.
Open Catalog 계정 만들기¶
Open Catalog 계정은 ORGADMIN만이 만들 수 있습니다.
Snowsight의 탐색 창에서 관리자 > 계정 을 선택합니다.
+ 계정 드롭다운에서 Snowflake Open Catalog 계정 만들기 를 선택합니다.
Snowflake Open Catalog 계정 만들기 대화 상자를 완성합니다.
클라우드: Apache Iceberg™ 테이블을 저장할 클라우드 공급자입니다.
리전: Iceberg 테이블을 저장할 리전입니다.
에디션: Open Catalog 계정용 에디션입니다.
다음 을 선택합니다.
새 계정 만들기 대화 상자에서 계정 이름, 사용자 이름, 비밀번호, 이메일 필드를 채웁니다.
계정 만들기 를 선택합니다. 새 Open Catalog 계정이 생성되고 확인 상자가 나타납니다.
확인 상자에서 계정 로케이터 URL 을 선택하여 웹 브라우저에서 계정 로케이터 URL을 엽니다.
계정 로케이터 URL을 북마크합니다. Open Catalog에 로그인할 때 계정 로케이터 URL을 지정해야 합니다.
Open Catalog 웹 인터페이스에 로그인하기¶
계정 생성 후 이메일을 통해 받으신 계정 URL을 클릭하거나 https://app.snowflake.com으로 이동합니다.
다른 계정으로 로그인 을 클릭하고 앞서 생성한 Open Catalog 계정으로 로그인합니다.
사용 사례 1: Apache Spark™를 사용하여 테이블 만들기¶
S3 위치에 대한 액세스 권한을 부여하는 IAM 정책 만들기¶
S3 위치에 대한 액세스 권한을 부여하는 IAM 정책이 아직 없다면 먼저 이러한 정책부터 하나 만듭니다. 이 정책을 만드는 방법에 대한 지침은 S3 위치에 대한 액세스 권한을 부여하는 IAM 정책 만들기 섹션을 참조하십시오.
IAM 역할 만들기¶
Open Catalog에 대한 AWS IAM 역할이 아직 없으면 이러한 역할을 만들어 S3 버킷에 대한 권한을 부여합니다. 지침은 IAM 역할 만들기를 참조하십시오. 지침에 정책을 선택하라는 내용이 나오면 S3 위치에 대한 액세스 권한을 부여하는 IAM 정책을 선택합니다.
Open Catalog에서 내부 카탈로그 만들기¶
Open Catalog 계정에서 내부 카탈로그를 사용하면 테이블을 만들고 쿼리하고 Apache Spark™ 또는 다른 쿼리 엔진을 사용하여 테이블에 대해 DML을 실행할 수 있습니다.
새로운 Open Catalog 계정에 로그인합니다.
새 카탈로그를 만들려면 왼쪽 창에서 카탈로그 를 선택합니다.
오른쪽 상단에서 +카탈로그 를 선택합니다.
카탈로그 만들기 대화 상자에서 다음 세부 정보를 입력합니다.
이름: 카탈로그 demo_catalog 의 이름.
기본 기준 위치: 테이블 데이터가 저장될 위치입니다.
추가 위치(선택 사항): 여러 저장소 위치가 나열된 쉼표로 구분된 목록입니다. 이는 이 카탈로그의 다른 위치에서 테이블을 가져와야 하는 경우에 주로 사용됩니다. 이 항목은 비워 둘 수 있습니다.
S3 역할 ARN: 저장소 위치에 대한 읽기/쓰기 액세스 권한이 있는 AWS 역할입니다. Open Catalog용으로 생성한 IAM 역할의 ARN을 입력합니다.
외부 ID: (선택 사항): 카탈로그 사용자와 저장소 계정 간에 신뢰 관계를 생성하는 동안 제공할 시크릿입니다. 이 항목을 건너뛸 경우 외부 ID는 자동으로 생성됩니다. 이 자습서에서는 abc123 과 같은 간단한 문자열을 사용합니다.
만들기 를 선택합니다. 카탈로그가 생성되고 다음 값이 카탈로그에 추가됩니다.
Open Catalog 계정의 IAM 사용자 ARN 입니다.
외부 ID를 직접 입력하지 않은 경우에는 카탈로그에 대한 외부 ID 가 자동으로 생성됩니다.
다음 섹션에서 신뢰 관계를 만들 때 이 값이 필요합니다.
신뢰 관계 만들기¶
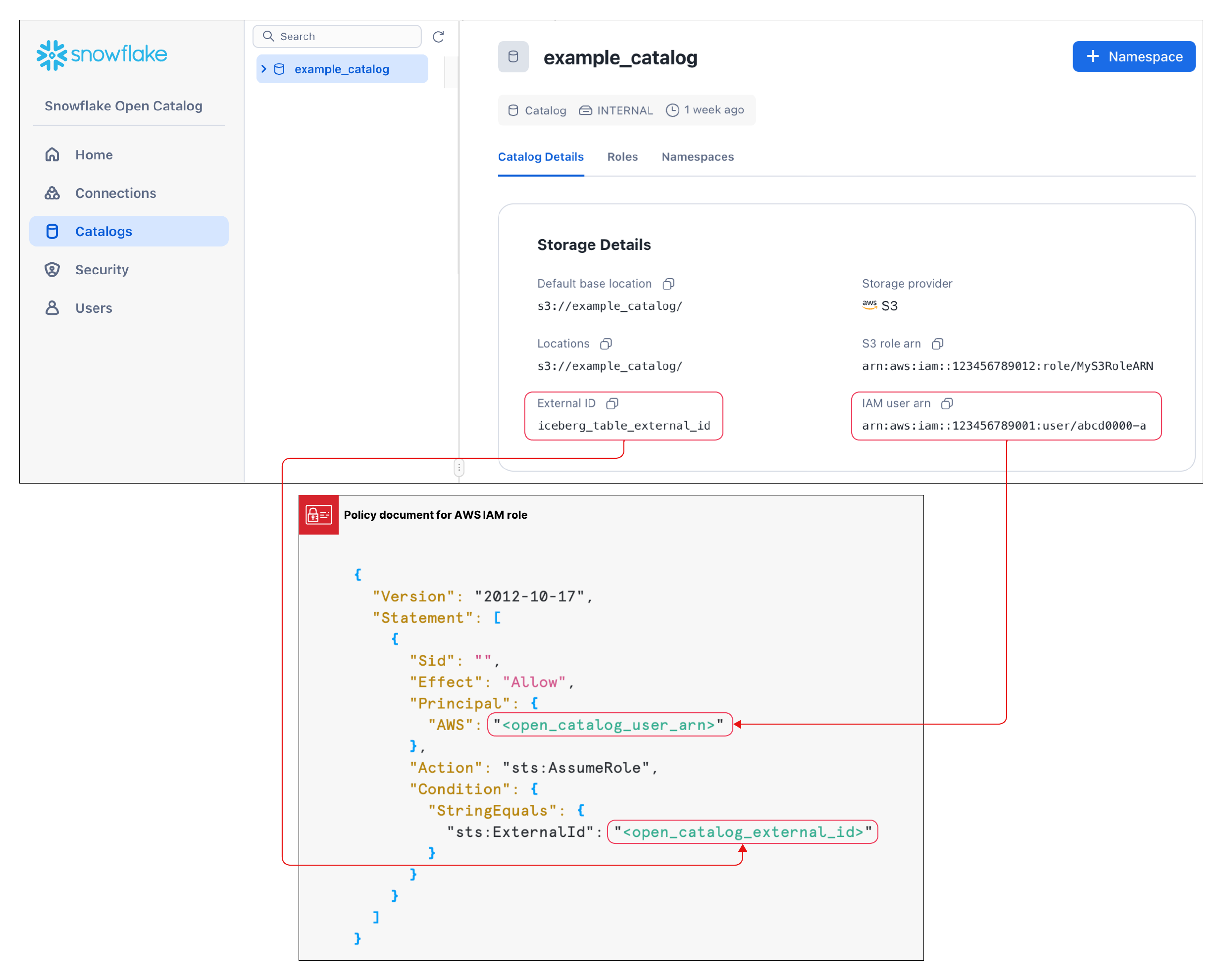
카탈로그를 만든 후에는 위 구성에서 지정한 S3 역할이 저장소 위치에서 데이터를 읽고 쓸 수 있도록 신뢰 관계를 설정해야 합니다. 이 작업을 완료하려면 S3 IAM 사용자 ARN과 카탈로그의 외부 ID가 필요합니다.
카탈로그가 생성된 후 목록에서 카탈로그를 선택하여 카탈로그의 S3 IAM 사용자 ARN과 외부 ID를 표시합니다.
신뢰 관계를 생성하려면 5단계: IAM 사용자에게 버킷 오브젝트에 액세스할 수 있는 권한 부여하기의 지침을 완료하십시오.
이들 지침에 표시된 JSON 오브젝트에서 다음을 수행합니다.
<open_catalog_user_arn>의 경우 Open Catalog UI에서 IAM 사용자 ARN 아래의 값을 사용합니다.<open_catalog_external_id>의 경우 Open Catalog UI에서 외부 ID 아래의 값을 사용합니다.
Apache Spark&trade에 대한 새로운 서비스 연결 구성하기¶
Apache Spark에서 방금 만든 카탈로그에 대한 쿼리를 실행하기 위해 새로운 연결(client_id/client_secret 페어)을 만듭니다.
Open Catalog의 왼쪽 창에서 연결 탭을 선택한 다음, 오른쪽 상단에서 + 연결 을 선택합니다.
서비스 연결 구성 대화 상자에서 새로운 주체 역할을 생성하거나 사용 가능한 역할 중 하나를 선택합니다.
만들기 를 선택합니다.
서비스 연결 구성 대화 상자에서 클라이언트 ID와 클라이언트 시크릿을 텍스트 편집기에 복사하려면 <CLIENT ID>:<SECRET>으로 필드 내에서 복사 를 선택합니다.
중요
이러한 텍스트 문자열은 나중에 Open Catalog 서비스에서 검색할 수 없으므로 지금 복사해야 합니다. Spark를 구성할 때 이러한 텍스트 문자열을 사용합니다.
연결을 위한 카탈로그 권한 설정하기¶
이제 카탈로그에 액세스할 수 있도록 서비스 연결에 권한을 부여합니다. 액세스 권한이 없으면 서비스 연결에서 카탈로그에 대한 쿼리를 실행할 수 없습니다.
탐색 창에서 카탈로그 를 선택한 다음 목록에서 카탈로그를 선택합니다.
새 역할을 만들려면 역할 탭을 선택합니다.
+ 카탈로그 역할 을 선택합니다.
카탈로그 역할 만들기 대화 상자에서 이름 에 spark_catalog_role 을 입력합니다.
권한 에서 CATALOG_MANAGE_CONTENT 를 선택한 다음 만들기 를 선택합니다.
이렇게 하면 테이블을 만들고 읽고 쓸 수 있는 권한이 역할에 부여됩니다.
주체 역할에 권한 부여 를 선택합니다.
카탈로그 역할 부여 대화 상자에서 권한을 부여받을 주체 역할 에 my_spark_admin_role 을 선택합니다.
권한을 부여할 카탈로그 역할 에 spark_catalog_role 을 선택한 다음 권한 부여 를 선택합니다.
이 절차의 결과로, my_spark_admin_role에 spark_catalog_role 역할이 부여되며, 이를 통해 이전 절차에서 만든 Spark 연결에 대한 관리자 권한이 주어집니다.
Spark 설정하기¶
터미널에서 다음 명령을 실행하여 설정에서 만든 가상 환경을 활성화하고 Jupyter Notebooks를 엽니다.
conda activate iceberg-lab
jupyter notebook
Spark 구성하기¶
서비스 연결을 등록하려면 Jupyter 노트북에서 다음 명령을 실행하십시오.
import os os.environ['SPARK_HOME'] = '/Users/<username>/opt/anaconda3/envs/iceberg-lab/lib/python3.12/site-packages/pyspark' import pyspark from pyspark.sql import SparkSession spark = SparkSession.builder.appName('iceberg_lab') \ .config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \ .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \ .config('spark.sql.defaultCatalog', 'opencatalog') \ .config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \ .config('spark.sql.catalog.opencatalog.type', 'rest') \ .config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \ .config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \ .config('spark.sql.catalog.opencatalog.credential','<client_id>:<client_secret>') \ .config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \ .config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \ .getOrCreate() #Show namespaces spark.sql("show namespaces").show() #Create namespace spark.sql("create namespace spark_demo") #Use namespace spark.sql("use namespace spark_demo") #Show tables; this will show no tables since it is a new namespace spark.sql("show tables").show() #create a test table spark.sql("create table test_table (col1 int) using iceberg"); #insert a record in the table spark.sql("insert into test_table values (1)"); #query the table spark.sql("select * from test_table").show();
자세한 내용을 보려면 Spark에서 서비스 연결 등록하기 섹션을 참조하십시오.
매개 변수¶
매개 변수 |
설명 |
|---|---|
|
연결할 카탈로그의 이름을 지정합니다. |
|
외부 클라우드 저장소 공급자에 대한 Maven 좌표를 지정합니다.
|
|
서비스 주체가 사용할 클라이언트 ID 를 지정합니다. |
|
서비스 주체가 사용할 클라이언트 시크릿을 지정합니다. |
|
Open Catalog 계정의 계정 식별자를 지정합니다. |
|
서비스 주체에 부여되는 주체 역할을 지정합니다. |
선택 사항: S3 크로스 리전¶
오픈 카탈로그 계정이 Amazon S3에서 호스팅되지만 S3 버킷이 위치한 리전과 다른 리전에 위치한 경우, 추가 Spark 구성 설정을 제공해야 합니다.
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
<target_s3_region> 은 S3 버킷이 위치한 리전을 지정합니다. 리전 코드 목록은 AWS 설명서의 리전별 엔드포인트 섹션을 참조하십시오.
다음 코드 예제는 s3 리전을 포함하도록 수정한 것입니다.
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('iceberg_lab') \
.config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', 'opencatalog') \
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.opencatalog.type', 'rest') \
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \
.config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \
.config('spark.sql.catalog.opencatalog.credential','<client_id>:<secret>') \
.config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \
.config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
.getOrCreate()
Snowflake를 사용하여 테이블 쿼리하기¶
Snowflake에서 카탈로그 통합 오브젝트를 생성하고 Snowflake에서 Open Catalog의 테이블을 나타내는 Apache Iceberg™ 테이블을 생성할 수 있습니다. 다음 예에서는 Open Catalog의 내부 카탈로그에서 Spark가 방금 만든 Iceberg 테이블을 나타내는 Iceberg 테이블을 Snowflake에 만듭니다.
동일한 Spark 연결 자격 증명을 사용하거나 새로운 Snowflake 연결을 만들 수 있습니다. 새 연결을 만드는 경우 그에 따라 역할과 권한을 설정해야 합니다.
카탈로그 통합 오브젝트를 만듭니다.
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_int CATALOG_SOURCE = POLARIS TABLE_FORMAT = ICEBERG CATALOG_NAMESPACE = '<catalog_namespace>' REST_CONFIG = ( CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog' CATALOG_NAME = ‘<catalog_name>’ ) REST_AUTHENTICATION = ( TYPE = OAUTH OAUTH_CLIENT_ID = '<client_id>' OAUTH_CLIENT_SECRET = '<secret>' OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL') ) ENABLED = TRUE; # the <catalog_namespace> created in previous step is spark_demo. # the <catalog_name> created in previous step is demo_catalog.
위에서 만든 카탈로그 통합을 사용하여 Snowflake에서 테이블 표현을 만들고 테이블을 쿼리합니다.
CREATE OR REPLACE ICEBERG TABLE test_table CATALOG = 'demo_open_catalog_int' EXTERNAL_VOLUME = '<external_volume>' CATALOG_TABLE_NAME = 'test_table'; SELECT * FROM test_table;
사용 사례 2: Snowflake에서 Open Catalog로 Apache Iceberg™ 테이블 동기화¶
Snowflake에 Iceberg 테이블이 있는 경우 다른 엔진에서 테이블을 쿼리할 수 있도록 테이블을 Open Catalog로 동기화할 수 있습니다.
Open Catalog에서 외부 카탈로그 만들기¶
Snowflake의 Iceberg 테이블은 Open Catalog 계정의 외부 카탈로그에서 동기화할 수 있습니다.
새로운 Open Catalog 계정에 로그인합니다.
새 카탈로그를 만들려면 왼쪽 창에서 카탈로그 를 선택합니다.
오른쪽 상단에서 +카탈로그 를 선택합니다.
카탈로그 만들기 대화 상자에서 다음 세부 정보를 입력합니다.
이름: 카탈로그의 이름을 demo_catalog_ext 로 지정합니다.
외부 토글을 켜기 로 설정합니다.
기본 기준 위치: 테이블 데이터가 저장될 위치입니다.
참고
이 자습서의 사용 사례 1에서 만든 내부 카탈로그와 다른 저장소 위치를 사용해야 합니다. 카탈로그에 대해 정의된 액세스 권한이 올바르게 적용되도록 하려면 서로 다른 두 카탈로그의 위치가 겹치지 않도록 해야 합니다.
추가 위치(선택 사항): 여러 저장소 위치가 나열된 쉼표로 구분된 목록입니다. 이는 이 카탈로그의 다른 위치에서 테이블을 가져와야 하는 경우에 주로 사용됩니다. 이 항목은 비워 둘 수 있습니다.
S3 역할 ARN: 저장소 위치에 대한 읽기/쓰기 액세스 권한이 있는 AWS 역할입니다.
외부 ID: (선택 사항): 카탈로그 사용자와 저장소 계정 간에 신뢰 관계를 생성하는 동안 제공할 시크릿입니다. 이 항목을 건너뛸 경우 외부 ID는 자동으로 생성됩니다. 이 자습서에서는 abc123 과 같은 간단한 문자열을 사용합니다.
만들기 를 선택합니다. 카탈로그에 다음 값이 추가됩니다.
Open Catalog 계정의 IAM 사용자 ARN 입니다.
외부 ID를 직접 입력하지 않은 경우에는 카탈로그에 대한 외부 ID 가 자동으로 생성됩니다.
Snowflake에 대한 새로운 서비스 연결 구성하기¶
Open Catalog의 왼쪽 창에서 연결 탭을 선택한 다음, 오른쪽 상단에서 + 연결 을 선택합니다.
서비스 연결 구성 대화 상자에서 새로운 주체 역할을 생성하거나 사용 가능한 역할 중 하나를 선택합니다.
만들기 를 선택합니다.
서비스 연결 구성 대화 상자에서 클라이언트 ID와 클라이언트 시크릿을 텍스트 편집기에 복사하려면 <CLIENT ID>:<SECRET>으로 필드 내에서 복사 를 선택합니다.
중요
이러한 텍스트 문자열은 나중에 Open Catalog 서비스에서 검색할 수 없으므로 지금 복사해야 합니다. Spark를 구성할 때 이러한 텍스트 문자열을 사용합니다.
카탈로그 권한 설정하기¶
Snowflake 연결이 외부 카탈로그에 대한 올바른 권한을 갖도록 외부 카탈로그에 대한 권한을 설정하려면 다음 단계를 따르십시오.
탐색 창에서 카탈로그 를 선택한 다음 목록에서 외부 카탈로그를 선택합니다.
새 역할을 만들려면 역할 탭을 선택합니다.
+ 카탈로그 역할 을 선택합니다.
카탈로그 역할 만들기 대화 상자에서 이름 에 spark_catalog_role 을 입력합니다.
권한 에서 CATALOG_MANAGE_CONTENT 를 선택한 다음 만들기 를 선택합니다.
이렇게 하면 테이블을 만들고 읽고 쓸 수 있는 권한이 역할에 부여됩니다.
주체 역할에 권한 부여 를 선택합니다.
카탈로그 역할 부여 대화 상자에서 권한을 부여받을 주체 역할 에 my_spark_admin_role 을 선택합니다.
권한을 부여할 카탈로그 역할 에 spark_catalog_role 을 선택한 다음 권한 부여 를 선택합니다.
Snowflake에서 카탈로그 통합 오브젝트 만들기¶
Snowflake에서 CREATE CATALOG INTEGRATION (Snowflake Open Catalog) 명령 을 사용하여 카탈로그 통합 오브젝트를 만듭니다. CATALOG_NAME 의 경우 Open Catalog 계정에서 구성한 외부 카탈로그의 이름(demo_catalog_ext)을 지정합니다.
Snowflake는 테이블과 해당 상위 항목의 네임스페이스를 Open Catalog에서 이 외부 카탈로그에 동기화합니다. 예를 들어, Snowflake에 등록된 open_catalog_demo.iceberg.test_table_managed Iceberg 테이블이 있고 카탈로그 통합에서 demo_catalog_ext 을 지정하면 Snowflake는 이 테이블을 다음과 같은 정규화된 이름(demo_catalog_ext.open_catalog_demo.iceberg.test_table_managed)으로 Open Catalog와 동기화합니다.
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_ext
CATALOG_SOURCE=POLARIS
TABLE_FORMAT=ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog'
CATALOG_NAME = '<catalog_name>'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<client_id>'
OAUTH_CLIENT_SECRET = '<secret>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED=TRUE;
# the <catalog_name> created in previous step is demo_catalog_ext.
카탈로그 동기화 설정하기¶
Snowflake가 관리하는 Iceberg 테이블을 Open Catalog에 동기화하려면 먼저 Open Catalog에서 Snowflake가 테이블을 동기화할 외부 카탈로그를 지정해야 합니다.
카탈로그 동기화를 설정하려면 ALTER DATABASE 명령을 CATALOG_SYNC 매개 변수와 함께 사용합니다. 이 매개 변수의 값은 Open Catalog용 카탈로그 통합의 이름을 지정합니다. 예:
ALTER DATABASE open_catalog_demo SET CATALOG_SYNC = 'demo_open_catalog_ext';
이 코드를 실행하면 Snowflake는 open_catalog_demo 데이터베이스의 모든 Snowflake 관리 Iceberg 테이블을 demo_open_catalog_ext 카탈로그 통합에서 지정한 Open Catalog의 <카탈로그_이름> 외부 카탈로그에 동기화합니다.
Snowflake로 관리되는 Iceberg 테이블 만들기¶
Snowflake로 관리되는 Iceberg 테이블을 만들고 Snowflake에서 이를 Open Catalog로 동기화합니다. 자세한 내용은 다음을 참조하십시오.
중요
외부 볼륨의
STORAGE_BASE_URL은 Open Catalog에서 생성한 외부 카탈로그의 기본 기준 위치 와 일치해야 합니다.
use database open_catalog_demo;
use schema iceberg;
# Note that the storage location for this external volume will be different than the storage location for the external volume in use case 1
CREATE OR REPLACE EXTERNAL VOLUME snowflake_demo_ext
STORAGE_LOCATIONS =
(
(
NAME = '<storage_location_name>'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://<s3_location>'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<aws_acct>:role/<rolename>'
STORAGE_AWS_EXTERNAL_ID = '<external_id>'
)
);
CREATE OR REPLACE ICEBERG TABLE test_table_managed (col1 int)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'snowflake_demo_ext'
BASE_LOCATION = 'test_table_managed'
Snowflake에서 테이블을 수정하면 변경 사항이 Open Catalog 계정의 외부 카탈로그와 자동으로 동기화됩니다. Apache Spark™와 같은 다른 엔진은 Open Catalog 에 연결하여 테이블을 쿼리할 수 있습니다.
참고
테이블이 Open Catalog에 동기화하는 데 실패할 경우 SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG 시스템 함수를 실행하여 동기화 실패 원인을 진단합니다. 자세한 내용은 SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG 섹션을 참조하십시오.
결론¶
Open Catalog 계정에서 내부 카탈로그를 사용하면 테이블을 만들고 쿼리하고 Apache Spark™ 또는 다른 쿼리 엔진을 사용하여 테이블에 대해 DML을 실행할 수 있습니다.
Snowflake에서는 Open Catalog에 대한 카탈로그 통합을 생성하여 다음 작업을 수행할 수 있습니다.
Open Catalog 관리형 테이블에서 쿼리를 실행합니다.
Open Catalog 계정에서 Snowflake 테이블을 외부 카탈로그와 동기화합니다.
알아본 내용¶
Open Catalog 계정을 만듭니다.
Open Catalog 계정에서 내부 카탈로그를 만듭니다.
Spark를 사용하여 내부 카탈로그에 테이블을 만듭니다.
Snowflake를 사용해 Open Catalog에 대한 카탈로그 통합을 만들어 Open Catalog 계정의 내부 카탈로그에 생성된 테이블에서 쿼리를 실행합니다.
Open Catalog 계정에서 외부 카탈로그를 만듭니다.
Snowflake에서 관리되는 Apache Iceberg™ 테이블을 만들고 두 개의 상위 네임스페이스와 함께 이를 Open Catalog 계정의 외부 카탈로그와 동기화합니다. 이 자습서에서는 데이터베이스 수준에서 카탈로그 동기화를 설정하는 방법을 배웠습니다. 그러나 계정, 스키마 또는 테이블 수준에서 설정하고 하나의 상위 네임스페이스와 동기화할 수도 있습니다. 자세한 내용은 다음 항목을 참조하십시오.
스키마 수준에서 카탈로그 동기화를 설정하는 예는 Snowflake 설명서의 스키마 수준에서 카탈로그 동기화 설정하기 를 참조하십시오.
카탈로그 동기화 설정에 대한 자세한 내용은 Snowflake 설명서의 CATALOG_SYNC 섹션을 참조하십시오.
테이블을 하나의 상위 네임스페이스와 동기화하려면 CREATE DATABASE 명령으로 CATALOG_SYNC_NAMESPACE_MODE 속성을 설정합니다. 자세히 알아보려면 CREATE DATABASE 섹션을 참조하십시오.
참고
서드 파티 쿼리 엔진이 카탈로그에서 두 번째 네임스페이스 수준까지만 위치한 테이블을 쿼리할 수 있는 경우 테이블을 하나의 상위 네임스페이스와 동기화해야 합니다. 그렇지 않으면 Snowflake가 테이블을 Open Catalog의 세 번째 네임스페이스 수준으로 동기화하므로 테이블을 쿼리할 수 없습니다.