Erste Schritte mit Snowflake Open Catalog¶
Überblick¶
Snowflake Open Catalog ist ein offener Katalog für Apache Iceberg™. Open Catalog ist als SaaS-Dienst verfügbar, der auf Snowflake verwaltet wird. Es ist auch als Open Source-Code verfügbar, den Sie selbst erstellen und einsetzen können. Open Catalog bietet eine Implementierung des Apache Iceberg REST-Katalogs mit systemübergreifender Sicherheit durch rollenbasierte Zugriffssteuerung.
In diesem Tutorial lernen Sie, wie Sie mit dem auf Snowflake verwalteten Open Catalog beginnen.
Was Sie lernen werden¶
Wie Sie ein neues Open Catalog-Konto erstellen.
So erstellen Sie einen neuen Iceberg-Katalog im Open Catalog-Konto und sichern ihn mit RBAC.
So verwenden Sie Apache Spark™, um Tabellen im Katalog zu erstellen und Abfragen durchzuführen.
Wie Sie Snowflake verwenden, um Abfragen auf Tabellen im Katalog durchzuführen.
So spiegeln oder veröffentlichen Sie in Snowflake verwaltete Iceberg-Tabellen in Open Catalog.
Was Sie brauchen¶
ORGADMIN-Berechtigungen in Ihrer Snowflake-Organisation (um ein neues Open Catalog-Konto zu erstellen).
ACCOUNTADMIN-Berechtigungen in Ihrem Snowflake-Konto (zur Verbindung mit dem Open Catalog-Konto). Dieses Snowflake-Konto muss nicht mit dem Konto der Snowflake-Organisation identisch sein.
Was Sie tun werden¶
Sie werden zwei Anwendungsfälle abschließen:
Anwendungsfall 1: Erstellen Sie einen Katalog in Open Catalog, erstellen Sie eine Tabelle mit Apache Spark, und fragen Sie die Tabelle mit Apache Spark und Snowflake ab.
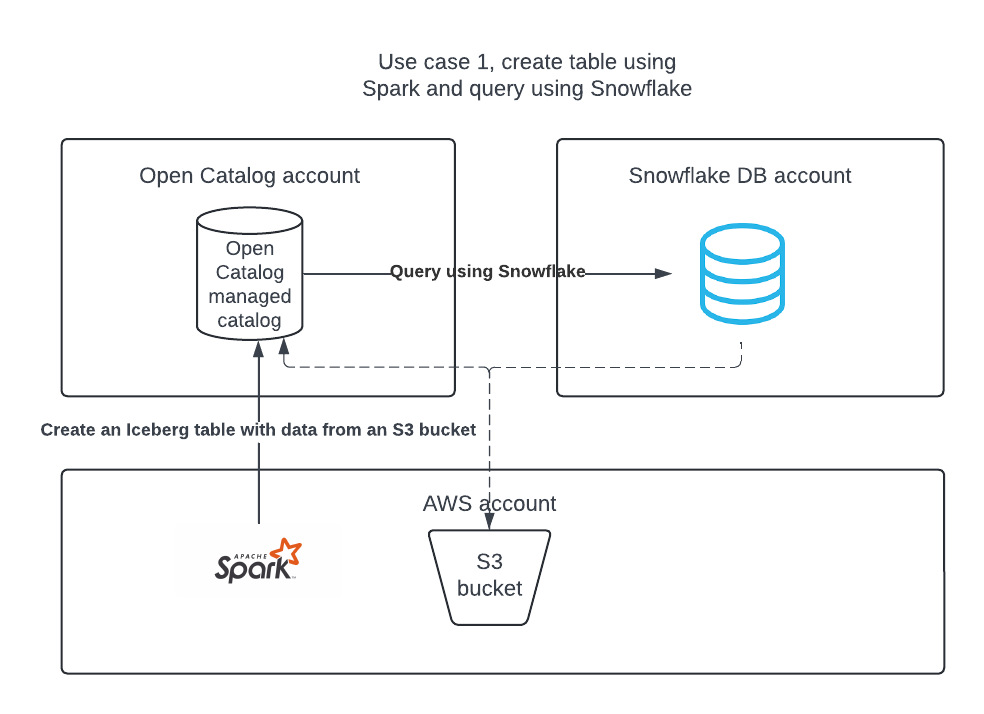
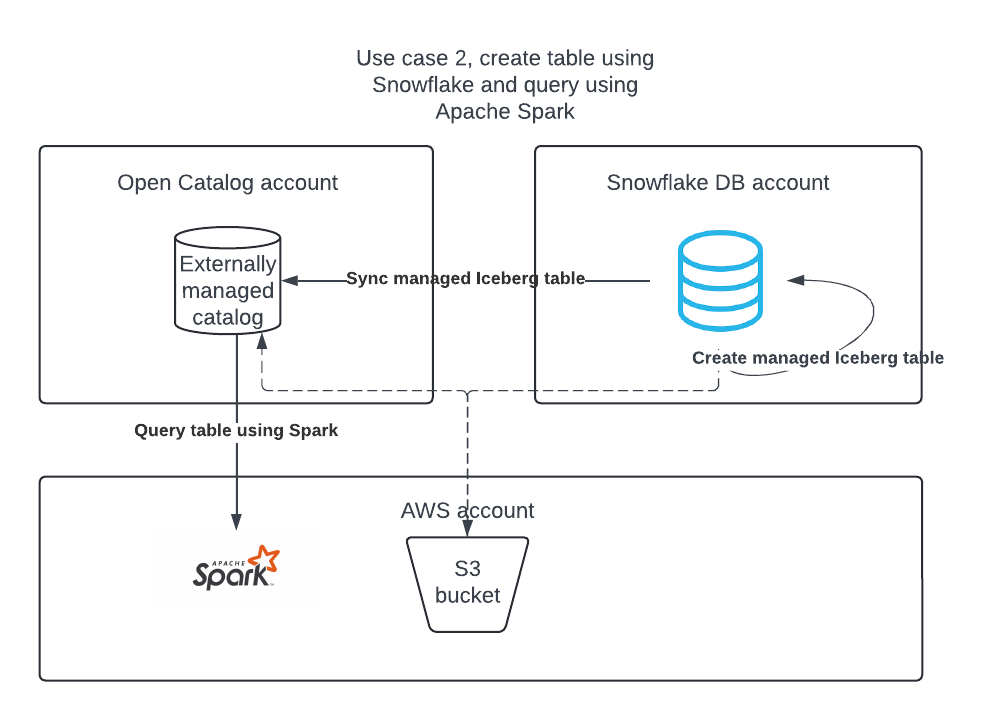
Anwendungsfall 2: Erstellen Sie mit Snowflake eine Apache Iceberg-Tabelle im Snowflake DB-Konto, und veröffentlichen Sie sie in Open Catalog, damit Apache Spark Abfragen darauf ausführen kann.
Umgebung einrichten¶
Installieren Sie Conda, Spark und Jupyter auf Ihrem Laptop¶
In diesem Tutorial können Sie mit Conda ganz einfach eine Entwicklungsumgebung erstellen und die erforderlichen Pakete herunterladen. Dies ist nur erforderlich, wenn Sie den Anwendungsfall 2 für die Verwendung von Apache Spark™ befolgen, um von Snowflake verwaltete Apache Iceberg™-Tabellen zu lesen. Dies ist nicht erforderlich, um Iceberg-Tabellen auf Snowflake zu erstellen oder zu verwenden.
Um Conda zu installieren, verwenden Sie die Anweisungen für Ihr OS:
Erstellen Sie eine Datei namens
environment.ymlmit folgendem Inhalt:name: iceberg-lab channels: - conda-forge dependencies: - findspark=2.0.1 - jupyter=1.0.0 - pyspark=3.5.0 - openjdk=11.0.13
Um die benötigte Umgebung zu erstellen, führen Sie Folgendes in Ihrer Shell aus:
conda env create -f environment.yml
Ein Konto für Open Catalog erstellen¶
Ein Open Catalog-Konto kann nur von einem ORGADMIN erstellt werden.
Wählen Sie in Snowsight im Navigationsbereich Admin > Konten.
Wählen Sie in der Dropdown-Liste + Konto die Option Snowflake Open Catalog-Konto erstellen.
Füllen Sie das Dialogfeld Snowflake Open Catalog-Konto erstellen aus:
Cloud: Der Cloud-Anbieter, bei dem Sie Apache Iceberg™-Tabellen speichern möchten.
Region: Die Region, in der Sie Iceberg-Tabellen speichern möchten.
Edition: Die Edition Ihres Open Catalog-Kontos.
Wählen Sie Nächste.
Füllen Sie im Dialogfeld „Neues Konto erstellen“ die Felder „Kontoname“, „Benutzername“, „Kennwort“ und „E-Mail“ aus.
Wählen Sie Konto einrichten. Ihr neues Open Catalog-Konto wird erstellt, und ein Bestätigungsfenster wird angezeigt.
Wählen Sie im Bestätigungsfeld die Option Kontosuche URL, um die Kontosuche URL in Ihrem Browser zu öffnen.
Setzen Sie ein Lesezeichen für den Speicherort des Kontos URL. Wenn Sie sich bei Open Catalog anmelden, müssen Sie die Konto-Locator-URL angeben.
Melden Sie sich bei der Weboberfläche von Open Catalog an¶
Klicken Sie auf das Konto URL, das Sie nach der Einrichtung des Kontos per E-Mail erhalten haben, OR gehen Sie zu https://app.snowflake.com.
Klicken Sie auf Bei einem anderen Konto anmelden, und melden Sie sich mit dem zuvor erstellten Konto für Open Catalog an.
Anwendungsfall 1: Erstellen Sie eine Tabelle mit Apache Spark™¶
IAM-Richtlinie erstellen, die Zugriff auf den S3-Speicherort gewährt¶
Wenn Sie noch keine haben, erstellen Sie zunächst eine IAM-Richtlinie, die den Zugriff auf Ihren S3-Speicherort gewährt. Anweisungen zur Erstellung dieser Richtlinie finden Sie unter IAM-Richtlinie erstellen, die Zugriff auf Ihren S3-Speicherort gewährt.
-IAM Rolle erstellen¶
Falls Sie noch keine haben, erstellen Sie eine AWS IAM-Rolle für Open Catalog, um Berechtigungen für Ihren S3-Bucket zu vergeben. Anweisungen finden Sie unter Erstellen einer IAM-Rolle. Wenn Sie in den Anweisungen aufgefordert werden, eine Richtlinie auszuwählen, wählen Sie die Richtlinie IAM, die den Zugriff auf Ihren S3-Speicherort gewährt.
Erstellen Sie einen internen Katalog in Open Catalog¶
Sie können einen internen Katalog in Ihrem Open Catalog-Konto verwenden, um Tabellen zu erstellen, sie abzufragen und DML auf den Tabellen mit Apache Spark™ oder anderen Abfrage-Engines laufen zu lassen.
Melden Sie sich bei Ihrem neuen Open Catalog-Konto an.
Um einen neuen Katalog zu erstellen, wählen Sie im linken Fensterbereich Kataloge.
Wählen Sie +Katalog in der oberen rechten Ecke.
Geben Sie im Dialog Katalog erstellen die folgenden Details ein:
Name: Nennen Sie den Katalog demo_catalog.
Standard-Speicherort: Der Speicherort, an dem die Tabellendaten gespeichert werden.
Zusätzliche Speicherorte (optional): Eine durch Komma getrennte Liste mit mehreren Speicherorten. Dies wird hauptsächlich verwendet, wenn Sie Tabellen von verschiedenen Speicherorten in diesem Katalog importieren müssen. Sie können das Feld leer lassen.
S3-Rollen-ARN: Eine AWS-Rolle, die Lese- und Schreibzugriff auf Speicherorte hat. Geben Sie die ARN der IAM-Rolle ein, die Sie für Open Catalog erstellt haben.
Externe ID: (optional): Ein Geheimnis, das Sie beim Aufbau einer Vertrauensbeziehung zwischen Katalogbenutzer und Speicherkonto angeben möchten. Wenn Sie dies auslassen, wird es automatisch generiert. Verwenden Sie für dieses Tutorial eine einfache Zeichenfolge wie abc123.
Wählen Sie Erstellen. Ihr Katalog wird erstellt, und die folgenden Werte werden zu Ihrem Katalog hinzugefügt:
Der IAM-Benutzer-ARN für Ihr Open Catalog-Konto.
Wenn Sie nicht selbst eine externe ID eingegeben haben, wird automatisch eine externe ID für Ihren Katalog generiert.
Sie werden diese Werte im nächsten Abschnitt benötigen, wenn Sie eine vertrauenswürdige Beziehung erstellen.
Erstellen Sie eine vertrauenswürdige Beziehung¶
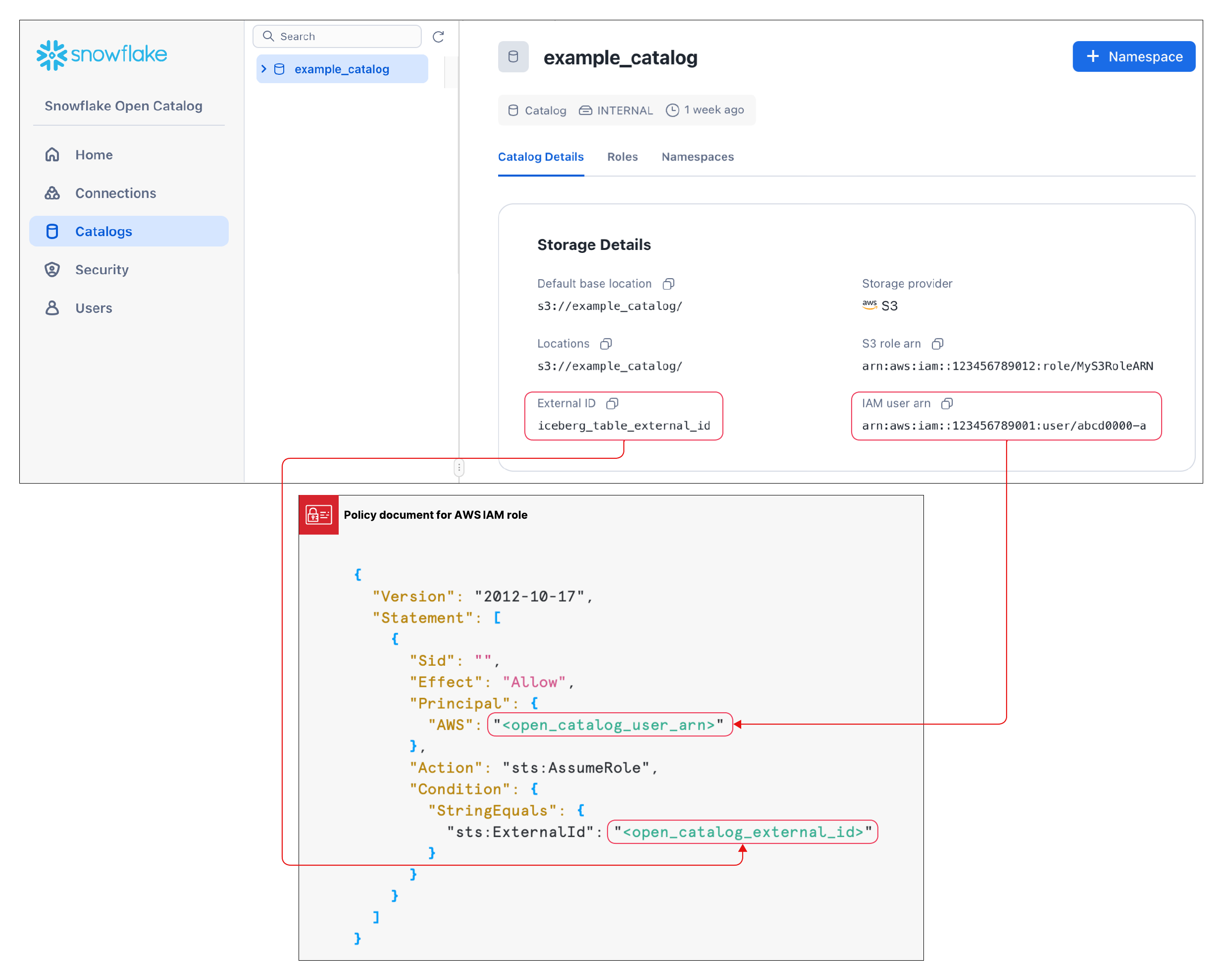
Nachdem Sie einen Katalog erstellt haben, müssen Sie eine vertrauenswürdige Beziehung einrichten, damit die in der obigen Konfiguration angegebene S3-Rolle Daten im Speicherort lesen und schreiben kann. Beachten Sie, dass Sie zur Durchführung dieser Aufgabe den S3 IAM-Benutzer-ARN und die externe ID für Ihren Katalog benötigen.
Nachdem der Katalog erstellt wurde, wählen Sie Ihren Katalog in der Liste aus, um die S3 IAM-Benutzer-ARN und die externe ID für Ihren Katalog anzuzeigen.
Um die vertrauenswürdige Beziehung zu erstellen, führen Sie die Anweisungen in Schritt 5: IAM-Benutzerberechtigungen für den Zugriff auf Bucket-Objekte erteilen aus.
In dem in dieser Anweisung gezeigten JSON-Objekt:
Für
<open_catalog_user_arn>verwenden Sie den Wert unter IAM-Benutzer-ARN im Open Catalog UI.Für
<open_catalog_external_id>verwenden Sie den Wert unter externe ID im Open Catalog UI.
Konfigurieren einer neuen Dienstverbindung für Apache Spark™¶
Erstellen Sie eine neue Verbindung (Paar client_id/client_secret) für Apache Spark, um Abfragen auf dem soeben erstellten Katalog durchzuführen.
Wählen Sie in Open Catalog im linken Fensterbereich die Registerkarte Verbindungen und dann oben rechts + Verbindung.
Im Dialog Dienstverbindung konfigurieren erstellen Sie eine neue Hauptrolle oder wählen eine der verfügbaren Rollen aus.
Wählen Sie Erstellen.
Wählen Sie im Dialogfeld Dienstverbindung konfigurieren die Option Kopieren im Feld Als <CLIENT-ID>:<SECRET>, um die Client-ID und das Client-Geheimnis in einen Texteditor zu kopieren.
Wichtig
Sie werden diese Zeichenfolgen später nicht mehr vom Open Catalog Service abrufen können, also müssen Sie sie jetzt kopieren. Sie verwenden diese Zeichenfolgen, wenn Sie Spark konfigurieren.
Einrichten von Katalogberechtigungen für die Verbindung¶
Jetzt erteilen Sie der Dienstverbindung Berechtigungen, damit sie auf den Katalog zugreifen kann. Ohne Zugriffsrechte kann die Dienstverbindung keine Abfragen im Katalog durchführen.
Wählen Sie im Navigationsbereich Kataloge, und wählen Sie dann Ihren Katalog in der Liste aus.
Um eine neue Rolle zu erstellen, wählen Sie die Registerkarte Rollen.
Wählen Sie + Katalogrolle.
Geben Sie im Dialog Katalogrolle erstellen für Name den Wert spark_catalog_role ein.
Wählen Sie unter Berechtigungen die Option CATALOG_MANAGE_CONTENT, und wählen Sie dann Erstellen.
Damit erhält die Rolle die Berechtigung, Tabellen zu erstellen, zu lesen und zu schreiben.
Wählen Sie Berechtigung für die Prinzipalrolle.
Wählen Sie im Dialog Katalogrolle zuweisen für Prinzipalrolle, um Berechtigung zu erhalten die Rolle my_spark_admin_role.
Für Zu gewährende Katalogrolle wählen Sie spark_catalog_role und dann Gewähren.
Als Ergebnis dieser Prozedur wird die Rolle spark_catalog_role der Rolle my_spark_admin_role zugewiesen, die Ihnen Admin-Berechtigungen für die Spark-Verbindung gibt, die Sie in der vorherigen Prozedur erstellt haben.
Spark einrichten¶
Führen Sie von Ihrem Terminal aus die folgenden Befehle aus, um die virtuelle Umgebung zu aktivieren, die Sie bei der Einrichtung erstellt haben, und öffnen Sie Jupyter Notebooks:
conda activate iceberg-lab
jupyter notebook
Spark konfigurieren¶
Um die Dienstverbindung zu registrieren, führen Sie die folgenden Befehle in einem Jupyter-Notebook aus.
import os os.environ['SPARK_HOME'] = '/Users/<username>/opt/anaconda3/envs/iceberg-lab/lib/python3.12/site-packages/pyspark' import pyspark from pyspark.sql import SparkSession spark = SparkSession.builder.appName('iceberg_lab') \ .config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \ .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \ .config('spark.sql.defaultCatalog', 'opencatalog') \ .config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \ .config('spark.sql.catalog.opencatalog.type', 'rest') \ .config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \ .config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \ .config('spark.sql.catalog.opencatalog.credential','<client_id>:<client_secret>') \ .config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \ .config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \ .getOrCreate() #Show namespaces spark.sql("show namespaces").show() #Create namespace spark.sql("create namespace spark_demo") #Use namespace spark.sql("use namespace spark_demo") #Show tables; this will show no tables since it is a new namespace spark.sql("show tables").show() #create a test table spark.sql("create table test_table (col1 int) using iceberg"); #insert a record in the table spark.sql("insert into test_table values (1)"); #query the table spark.sql("select * from test_table").show();
Weitere Informationen finden Sie unter Eine Dienstverbindung in Spark registrieren.
Parameter¶
Parameter |
Beschreibung |
|---|---|
|
Gibt den Namen des Katalogs an, mit dem eine Verbindung hergestellt werden soll. |
|
Gibt die Maven-Koordinate für Ihren externen Anbieter von Cloud Storage an:
|
|
Gibt die Client-ID an, die der Dienstprinzipal verwenden soll. |
|
Legt das Client-Geheimnis fest, das der Dienstprinzipal verwenden soll. |
|
Gibt den Bezeichner des Kontos für Ihr Open Catalog-Konto an. |
|
Gibt die Prinzipalrolle an, die dem Dienstprinzipal gewährt wird. |
Optional: Regionenübergreifender S3¶
Wenn Ihr Open Catalog-Konto auf Amazon S3 gehostet wird, sich aber in einer anderen Region befindet als die Region, in der sich Ihr S3 Storage-Bucket befindet, müssen Sie eine zusätzliche Spark-Konfigurationseinstellung vornehmen:
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
<target_s3_region> gibt die Region an, in der sich Ihr S3 Storage-Bucket befindet. Eine Liste der Codes für die Regionen finden Sie unter Regionale Endpunkte in der Dokumentation AWS.
Das folgende Codebeispiel wurde geändert, um die S3-Region einzubeziehen:
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('iceberg_lab') \
.config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', 'opencatalog') \
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.opencatalog.type', 'rest') \
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \
.config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \
.config('spark.sql.catalog.opencatalog.credential','<client_id>:<secret>') \
.config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \
.config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
.getOrCreate()
Abfrage der Tabellen mit Snowflake¶
Sie können ein Objekt zur Integration von Katalogen in Snowflake erstellen und eine Apache Iceberg™-Tabelle in Snowflake erstellen, die die Tabelle in Open Catalog darstellt. Im folgenden Beispiel erstellen Sie eine Iceberg-Tabelle in Snowflake, die die gerade von Spark erstellte Iceberg-Tabelle im internen Katalog in Open Catalog repräsentiert.
Sie können die gleichen Anmeldeinformationen für die Spark-Verbindung verwenden oder eine neue Snowflake-Verbindung erstellen. Wenn Sie eine neue Verbindung erstellen, müssen Sie die Rollen und Berechtigungen entsprechend einstellen.
Erstellen Sie ein Objekt für die Integration eines Katalogs:
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_int CATALOG_SOURCE = POLARIS TABLE_FORMAT = ICEBERG CATALOG_NAMESPACE = '<catalog_namespace>' REST_CONFIG = ( CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog' CATALOG_NAME = ‘<catalog_name>’ ) REST_AUTHENTICATION = ( TYPE = OAUTH OAUTH_CLIENT_ID = '<client_id>' OAUTH_CLIENT_SECRET = '<secret>' OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL') ) ENABLED = TRUE; # the <catalog_namespace> created in previous step is spark_demo. # the <catalog_name> created in previous step is demo_catalog.
Erstellen Sie die Tabellendarstellung in Snowflake unter Verwendung der oben erstellten Katalogintegration, und fragen Sie die Tabelle ab:
CREATE OR REPLACE ICEBERG TABLE test_table CATALOG = 'demo_open_catalog_int' EXTERNAL_VOLUME = '<external_volume>' CATALOG_TABLE_NAME = 'test_table'; SELECT * FROM test_table;
Anwendungsfall 2: Synchronisierung von Apache Iceberg™-Tabellen von Snowflake zu Open Catalog¶
Wenn Sie Iceberg-Tabellen in Snowflake haben, können Sie diese mit Open Catalog synchronisieren, damit andere Suchmaschinen diese Tabellen abfragen können.
Einen externen Katalog in Open Catalog erstellen¶
Die Iceberg-Tabellen von Snowflake können in einem externen Katalog in Ihrem Open Catalog-Konto synchronisiert werden.
Melden Sie sich bei Ihrem neuen Open Catalog-Konto an.
Um einen neuen Katalog zu erstellen, wählen Sie im linken Fensterbereich Kataloge.
Wählen Sie +Katalog in der oberen rechten Ecke.
Geben Sie im Dialog Katalog erstellen die folgenden Details ein:
Name: Name des Katalogs demo_catalog_ext.
Setzen Sie den Schalter für Extern auf Ein.
Standard-Speicherort: Der Speicherort, an dem die Tabellendaten gespeichert werden.
Hinweis
Sie müssen einen anderen Speicherort verwenden als den internen Katalog, den Sie im Anwendungsfall 1 dieses Tutorials erstellt haben. Um sicherzustellen, dass die für einen Katalog definierten Zugriffsrechte korrekt durchgesetzt werden, können zwei verschiedene Kataloge keine überlappenden Speicherorte haben.
Zusätzliche Speicherorte (optional): Eine durch Komma getrennte Liste mit mehreren Speicherorten. Dies wird hauptsächlich verwendet, wenn Sie Tabellen von verschiedenen Speicherorten in diesem Katalog importieren müssen. Sie können das Feld leer lassen.
S3-Rollen-ARN: Eine AWS-Rolle, die Lese- und Schreibzugriff auf Speicherorte hat.
Externe ID: (optional): Ein Geheimnis, das Sie beim Aufbau einer Vertrauensbeziehung zwischen Katalogbenutzer und Speicherkonto angeben möchten. Wenn Sie dies auslassen, wird es automatisch generiert. Verwenden Sie für dieses Tutorial eine einfache Zeichenfolge wie abc123.
Wählen Sie Erstellen. Die folgenden Werte werden zu Ihrem Katalog hinzugefügt:
Der IAM-Benutzer-ARN für Ihr Open Catalog-Konto.
Wenn Sie nicht selbst eine externe ID eingegeben haben, wird automatisch eine externe ID für Ihren Katalog generiert.
Konfigurieren einer neuen Dienstverbindung für Snowflake¶
Wählen Sie in Open Catalog im linken Fensterbereich die Registerkarte Verbindungen und dann oben rechts + Verbindung.
Im Dialog Dienstverbindung konfigurieren erstellen Sie eine neue Hauptrolle oder wählen eine der verfügbaren Rollen aus.
Wählen Sie Erstellen.
Wählen Sie im Dialogfeld Dienstverbindung konfigurieren die Option Kopieren im Feld Als <CLIENT-ID>:<SECRET>, um die Client-ID und das Client-Geheimnis in einen Texteditor zu kopieren.
Wichtig
Sie werden diese Zeichenfolgen später nicht mehr vom Open Catalog Service abrufen können, also müssen Sie sie jetzt kopieren. Sie verwenden diese Zeichenfolgen, wenn Sie Spark konfigurieren.
Einrichten von Katalogberechtigungen¶
Gehen Sie wie folgt vor, um die Berechtigungen für den externen Katalog einzustellen, damit die Verbindung mit Snowflake die richtigen Berechtigungen für einen externen Katalog hat:
Wählen Sie im Navigationsbereich Kataloge, und wählen Sie dann Ihren externen Katalog in der Liste aus.
Um eine neue Rolle zu erstellen, wählen Sie die Registerkarte Rollen.
Wählen Sie + Katalogrolle.
Geben Sie im Dialog Katalogrolle erstellen für Name den Wert spark_catalog_role ein.
Wählen Sie unter Berechtigungen die Option CATALOG_MANAGE_CONTENT, und wählen Sie dann Erstellen.
Damit erhält die Rolle die Berechtigung, Tabellen zu erstellen, zu lesen und zu schreiben.
Wählen Sie Berechtigung für die Prinzipalrolle.
Wählen Sie im Dialog Katalogrolle zuweisen für Prinzipalrolle, um Berechtigung zu erhalten die Rolle my_spark_admin_role.
Für Zu gewährende Katalogrolle wählen Sie spark_catalog_role und dann Gewähren.
Erstellen Sie ein Objekt zur Integration eines Katalogs in Snowflake¶
Erstellen Sie in Snowflake ein Katalogintegrationsobjekt mit dem Befehl CREATE CATALOG INTEGRATION (Snowflake Open Catalog). Für CATALOG_NAME geben Sie den Namen des externen Katalogs an, den Sie in Ihrem Open Catalog-Konto konfiguriert haben (demo_catalog_ext).
Snowflake synchronisiert die Tabelle und ihren übergeordneten Namespace mit diesem externen Katalog in Open Catalog. Wenn Sie beispielsweise eine open_catalog_demo.iceberg.test_table_managed Iceberg-Tabelle in Snowflake registriert haben und in der Katalogintegration demo_catalog_ext angeben, synchronisiert Snowflake die Tabelle mit Open Catalog mit dem folgenden vollqualifizierten Namen: demo_catalog_ext.open_catalog_demo.iceberg.test_table_managed.
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_ext
CATALOG_SOURCE=POLARIS
TABLE_FORMAT=ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog'
CATALOG_NAME = '<catalog_name>'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<client_id>'
OAUTH_CLIENT_SECRET = '<secret>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED=TRUE;
# the <catalog_name> created in previous step is demo_catalog_ext.
Katalogsynchronisierung einrichten¶
Bevor Sie eine von Snowflake verwaltete Iceberg-Tabelle mit Open Catalog synchronisieren können, müssen Sie den externen Katalog in Open Catalog angeben, mit dem Snowflake die Tabelle synchronisieren soll.
Um die Katalogsynchronisierung einzurichten, verwenden Sie den Befehl ALTER DATABASE befehl mit dem Parameter CATALOG_SYNC. Für den Wert dieses Parameters geben Sie den Namen der Katalogintegration für Open Catalog an. Beispiel:
ALTER DATABASE open_catalog_demo SET CATALOG_SYNC = 'demo_open_catalog_ext';
Nachdem Sie diesen Code ausgeführt haben, synchronisiert Snowflake alle von Snowflake verwalteten Iceberg-Tabellen in der Datenbank open_catalog_demo mit dem externen Katalog <catalog_name> in Open Catalog, den Sie in der Katalogintegration demo_open_catalog_ext angegeben haben.
Erstellen einer von Snowflake verwalteten Iceberg-Tabelle¶
Erstellen Sie eine von Snowflake verwaltete Iceberg-Tabelle und synchronisieren Sie sie von Snowflake mit Open Catalog. Weitere Informationen dazu finden Sie unter:
Wichtig
Die
STORAGE_BASE_URLfür das externe Volume muss mit dem Standard-Speicherort für den externen Katalog übereinstimmen, den Sie in Open Catalog erstellt haben.
use database open_catalog_demo;
use schema iceberg;
# Note that the storage location for this external volume will be different than the storage location for the external volume in use case 1
CREATE OR REPLACE EXTERNAL VOLUME snowflake_demo_ext
STORAGE_LOCATIONS =
(
(
NAME = '<storage_location_name>'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://<s3_location>'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<aws_acct>:role/<rolename>'
STORAGE_AWS_EXTERNAL_ID = '<external_id>'
)
);
CREATE OR REPLACE ICEBERG TABLE test_table_managed (col1 int)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'snowflake_demo_ext'
BASE_LOCATION = 'test_table_managed'
Wenn Sie die Tabelle in Snowflake ändern, werden die Änderungen automatisch mit dem externen Katalog in Ihrem Open Catalog-Konto synchronisiert. Andere Engines wie Apache Spark™ können die Tabelle abfragen, indem sie sich mit Open Catalog verbinden.
Hinweis
Wenn die Tabelle nicht mit Open Catalog synchronisiert werden kann, führen Sie die Systemfunktion SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG aus, um den Grund für die fehlgeschlagene Synchronisierung zu ermitteln. Weitere Informationen finden Sie unter SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG.
Fazit¶
Sie können einen internen Katalog in Ihrem Open Catalog-Konto verwenden, um Tabellen zu erstellen, sie abzufragen und DML auf den Tabellen mit Apache Spark™ oder anderen Abfrage-Engines laufen zu lassen.
In Snowflake können Sie eine Katalogintegration für Open Catalog erstellen, um die folgenden Aufgaben durchzuführen:
Führen Sie Abfragen auf von Open Catalog verwalteten Tabellen aus.
Synchronisieren Sie Snowflake-Tabellen mit einem externen Katalog in Ihrem Open Catalog-Konto.
Zusammenfassung¶
Erstellen Sie ein Open Catalog-Konto.
Erstellen Sie einen internen Katalog in Ihrem Open Catalog-Konto.
Verwenden Sie Spark, um Tabellen im internen Katalog zu erstellen.
Verwenden Sie Snowflake, um eine Katalogintegration für Open Catalog zu erstellen, um Abfragen auf einer Tabelle durchzuführen, die in einem internen Katalog in Ihrem Open Catalog-Konto erstellt wurde.
Erstellen Sie einen externen Katalog in Ihrem Open Catalog-Konto.
Erstellen Sie eine verwaltete Apache Iceberg™-Tabelle in Snowflake und synchronisieren Sie diese, zusammen mit zwei übergeordneten Namespaces, mit dem externen Katalog in Ihrem Open Catalog-Konto. In diesem Tutorial haben Sie gelernt, wie Sie die Katalogsynchronisierung auf Datenbankebene einrichten. Sie können ihn jedoch auch auf Konto-, Schema- oder Tabellenebene einrichten und mit einem übergeordneten Namespace synchronisieren. Weitere Informationen dazu finden Sie unter folgenden Themen:
Ein Beispiel für die Einrichtung der Katalogsynchronisierung auf Schemaebene finden Sie unter Einrichten der Katalogsynchronisierung auf Schemaebene in der Snowflake-Dokumentation.
Weitere Informationen zur Einrichtung der Katalogsynchronisierung finden Sie unter CATALOG_SYNC in der Snowflake-Dokumentation.
Um die Tabelle mit einem übergeordneten Namespace zu synchronisieren, stellen Sie die Eigenschaft CATALOG_SYNC_NAMESPACE_MODE mit dem Befehl CREATE DATABASE ein. Mehr dazu erfahren Sie unter CREATE DATABASE in der Snowflake-Dokumentation.
Bemerkung
Wenn Ihr Drittanbieter-Abfrageprogramm nur Tabellen abfragen kann, die sich bis zur zweiten Namespace-Ebene in einem Katalog befinden, müssen Sie die Tabelle mit einem übergeordneten Namespace synchronisieren. Andernfalls wird Snowflake die Tabelle mit der dritten Namespace-Ebene in Open Catalog synchronisieren und Sie können die Tabelle nicht abfragen.