Snowflakeオープンカタログをはじめるにあたり¶
概要¶
SnowflakeオープンカタログはApache Iceberg™のオープンカタログです。オープンカタログは、Snowflake上で管理される SaaS サービスとして利用できます。また、オープンソースコードとして提供されており、自分でビルドしてデプロイすることもできます。オープンカタログは、ロールベースのアクセス制御によるクロスエンジンセキュリティを備えたApache Iceberg REST カタログの実装を提供します。
このチュートリアルでは、Snowflakeで管理されるオープンカタログを使い始める方法を学びます。
学習内容¶
新しいオープンカタログアカウントの作成方法
オープンカタログアカウントで新しいIcebergカタログを作成し、 RBAC を使用してセキュリティ保護する方法。
カタログでテーブルを作成し、クエリを実行するためにApache Spark™を使用する方法。
Snowflakeを使用してカタログ内のテーブルに対してクエリを実行する方法。
SnowflakeでマネージドIcebergテーブルをオープンカタログにミラーリングまたは公開する方法。
次が必要になります¶
Snowflake組織の ORGADMIN 権限(新しいオープンカタログアカウントを作成するため)。
Snowflake組織の ACCOUNTADMIN 権限(オープンカタログアカウントに接続するため)。このSnowflakeアカウントは、Snowflake組織アカウントと同じである必要はありません。
作業内容¶
2つのユースケースを完成させます。
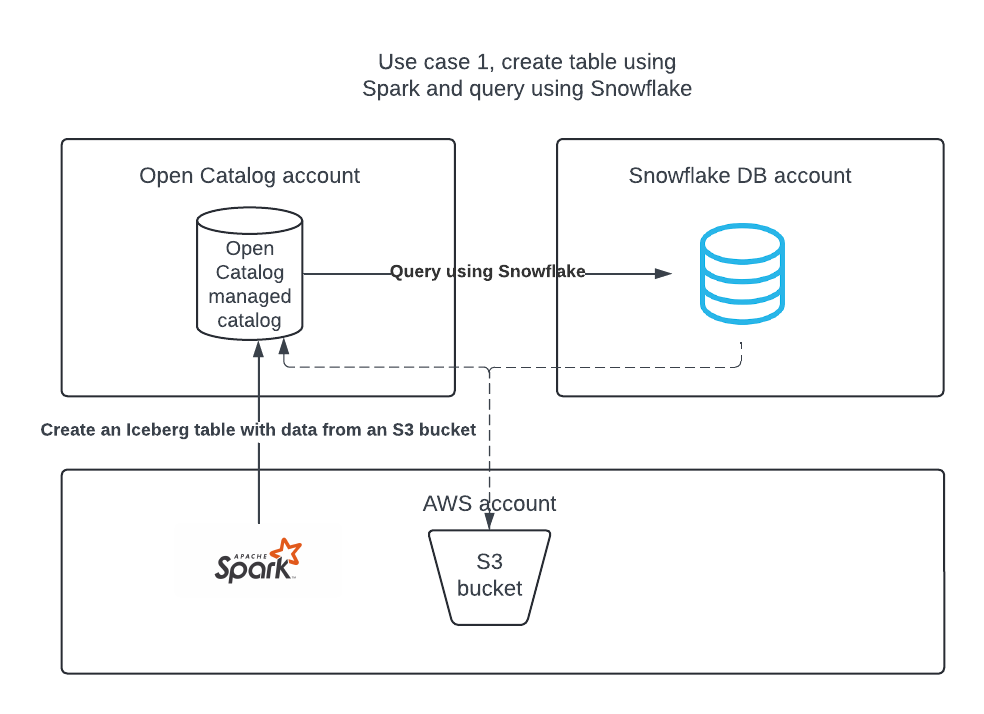
ユースケース1: オープンカタログでカタログを作成し、Apache Sparkを使用してテーブルを作成し、Apache SparkとSnowflakeを使用してテーブルにクエリを実行する。
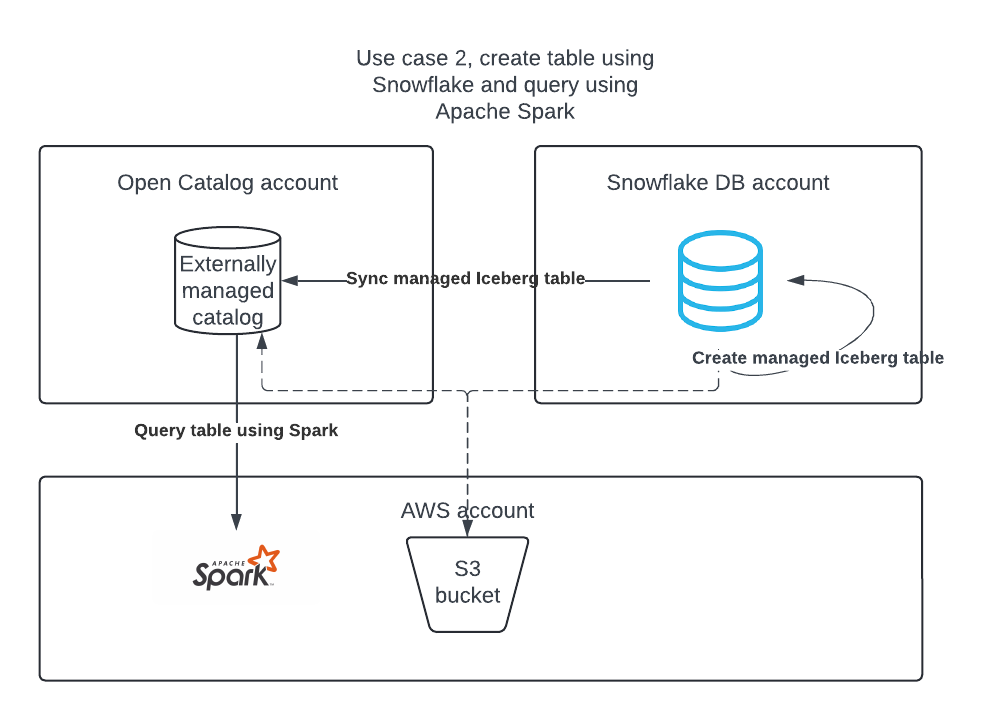
ユースケース2: Snowflakeを使用してSnowflake DB アカウントにApache Icebergテーブルを作成し、それをオープンカタログに公開してApache Sparkがそれに対してクエリを実行できるようにする。
環境の設定¶
ノートパソコンへのConda、Spark、Jupyterのインストール¶
このチュートリアルでは、簡単に開発環境を作成し、必要なパッケージをダウンロードするためにCondaを使用できます。これは、Apache Spark™を使用してSnowflakeが管理するApache Iceberg™のテーブルを読み取るためにユースケース2に従う場合にのみ必要です。これは、Snowflake上でIcebergテーブルを作成または使用するために必要ではありません。
オープンカタログアカウントの作成¶
オープンカタログアカウントは、 ORGADMIN によってのみ作成できます。
Snowsightのナビゲーションペインで、 管理者 > アカウント を選択します。
+アカウント ドロップダウンで、 Snowflakeオープンカタログアカウントを作成 を選択します。
Snowflake オープンカタログアカウント ダイアログを完了します。
クラウド: Apache Iceberg™テーブルを保管するクラウドプロバイダー。
リージョン: Icebergテーブルを保管するリージョン。
エディション: オープンカタログアカウントのエディション。
次へ を選択します。
新規アカウントを作成のダイアログで、アカウント名、ユーザー名、パスワード、およびメールフィールドを入力します。
アカウントを作成 を選択します。新しいオープンカタログアカウントが作成され、確認ボックスが表示されます。
確認ボックスで、 アカウントロケーター URL を選択し、ウェブブラウザでアカウントロケーター URL を開きます。
アカウントロケーター URL をブックマークします。オープンカタログにサインインする際には、アカウントロケーター URL を指定する必要があります。
オープンカタログのウェブインターフェイスにサインイン¶
アカウント作成後にメールで届いたアカウント URL をクリックする、 OR https://app.snowflake.comに移動します。
別のアカウントにサインイン をクリックし、先ほど作成したオープンカタログアカウントでサインインします。
ユースケース1: Apache Spark™を使用してテーブルを作成する¶
S3ロケーションへのアクセスを許可するIAMポリシーを作成する¶
まだ持っていない場合は、S3ロケーションへのアクセスを許可する IAM ポリシーを作成することから始めます。このポリシーの作成方法については、S3ロケーションへのアクセスを許可する IAM ポリシーを作成するを参照してください。
IAMロールを作成する¶
まだ持っていない場合は、オープンカタログ用の AWS IAM ロールを作成して、S3バケットに権限を付与します。手順については、 IAM ロールを作成する をご参照ください。ポリシーを選択するよう促されたら、S3ロケーションへのアクセスを許可する IAM ポリシーを選択します。
オープンカタログでの内部カタログの作成¶
オープンカタログアカウントの内部カタログを使用してテーブルを作成し、クエリを実行し、Apache Spark™またはその他のクエリエンジンを使用してテーブルに対して DML を実行することができます。
新しいオープンカタログアカウントにサインインします。
新しいカタログを作成するには、左側のペインで カタログ を選択します。
右上の +カタログ を選択します。
カタログを作成 ダイアログで、以下の詳細を入力します。
名前:カタログに demo_catalog という名前を付けます。
デフォルトのベースロケーション: テーブルデータが保管される場所。
追加のロケーション(オプション): 複数のストレージ場所をカンマ区切りで指定します。これは主に、このカタログの異なる場所からテーブルをインポートする必要がある場合に使用されます。空白のままにできます。
S3ロール ARN: ストレージ場所への読み書きアクセスを持つ AWS ロール。オープンカタログ用に作成した IAM ロールの ARN を入力します。
外部 ID: (オプション): カタログユーザーとストレージアカウントの信頼関係を作成する際に提供したい秘密。これをスキップすると自動生成されます。このチュートリアルでは、 abc123 のような単純な文字列を使用します。
作成 を選択します。カタログが作成され、以下の値がカタログに追加されます。
オープンカタログアカウントの IAM ユーザー名。
外部 ID を自分で入力しなかった場合、 外部 ID がカタログ用に自動生成されます。
この値は、次のセクションで信頼関係を作成するときに必要になります。
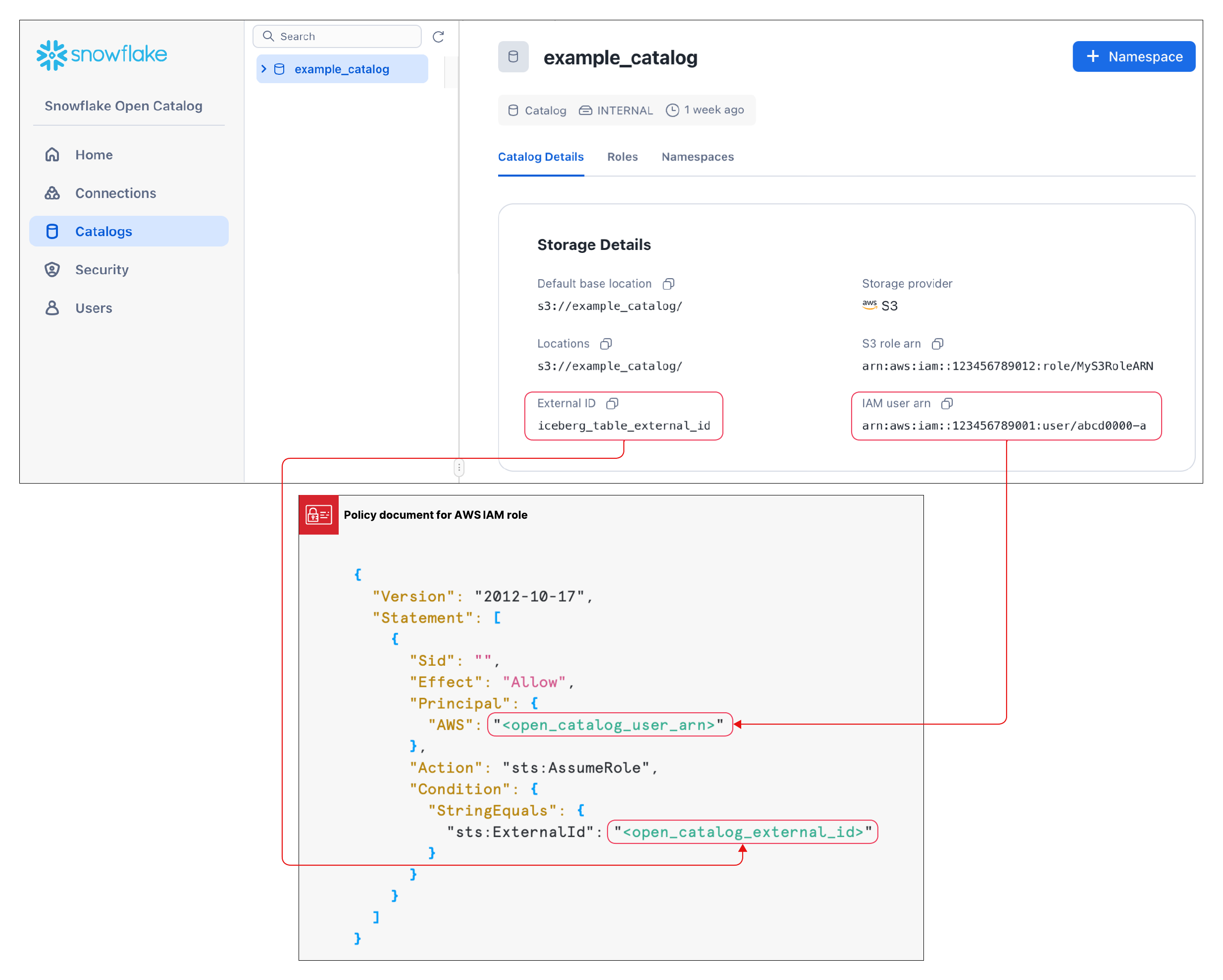
信頼関係の構築¶
カタログを作成したら、上記の構成で指定したS3ロールがストレージ場所のデータを読み書きできるように、信頼関係を設定する必要があります。このタスクを完了するには、カタログのS3 IAM ユーザーと外部 ID が必要になります。
カタログが作成された後、カタログをリストで選択すると、カタログのS3 IAM ユーザー名と外部 ID が表示されます。
信頼関係を作成するには、ステップ5: バケットオブジェクトにアクセスするための IAM ユーザー権限を付与する の手順を完了させます。
これらの手順に表示されている JSON オブジェクトには:
<open_catalog_user_arn>の場合、オープンカタログ UI の IAM ユーザーARN の下にある値を使用します。<open_catalog_external_id>の場合、オープンカタログ UI の 外部 ID の下にある値を使用します。
 。
。
Apache Spark™の新しいサービス接続を構成する¶
作成したカタログに対してクエリを実行するために、Apache Spark用の新しい接続(client_id/client_secretペア)を作成します。
オープンカタログの左ペインで、 接続 タブを選択し、右上の +接続 を選択します。
サービス接続を構成 ダイアログで、新しいプリンシパルロールを作成するか、利用可能なロールの1つから選択します。
作成 を選択します。
サービス接続を構成 ダイアログから、クライアント ID とクライアントシークレットをテキストエディタにコピーするには、 <CLIENT ID>:<SECRET>として フィールド内で コピー を選択します。
重要
これらのテキスト文字列を後でオープンカタログサービスから取り出すことはできないため、今すぐコピーしておく必要があります。これらのテキスト 文字列は、Sparkを設定する際に使用します。
接続のためのカタログ権限の設定¶
ここでは、サービス接続に権限を与え、カタログにアクセスできるようにします。アクセス権限がないと、サービス接続はカタログ上でクエリを実行できません。
ナビゲーションペインで、 カタログ を選択し、リストからカタログを選択します。
新しいロールを作成するには、 ロール タブを選択します。
+カタログロール を選択します。
カタログロールを作成 ダイアログで、 名前 に spark_catalog_role と入力します。
権限 では、 CATALOG_MANAGE_CONTENT を選択し、 作成 を選択します。
このロールには、テーブルの作成、読み取り、書き込みの権限が与えられます。
プリンシパルロールへに付与 を選択してします。
カタログロールを付与 ダイアログの 付与するプリンシパルロール で my_spark_admin_role を選択します。
付与するカタログロール では、 spark_catalog_role を選択し、 付与 を選択します。
このプロシージャの結果、spark_catalog_roleロールがmy_spark_admin_roleに付与され、前のプロシージャで作成したSpark接続の管理者権限が付与されます。
Sparkの設定¶
ターミナルから以下のコマンドを実行して、設定で作成した仮想環境をアクティブにし、Jupyter Notebooksを開きます。
conda activate iceberg-lab
jupyter notebook
Sparkの構成¶
サービス接続を登録するには、Jupyter Notebookで以下のコマンドを実行します。
import os os.environ['SPARK_HOME'] = '/Users/<username>/opt/anaconda3/envs/iceberg-lab/lib/python3.12/site-packages/pyspark' import pyspark from pyspark.sql import SparkSession spark = SparkSession.builder.appName('iceberg_lab') \ .config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \ .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \ .config('spark.sql.defaultCatalog', 'opencatalog') \ .config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \ .config('spark.sql.catalog.opencatalog.type', 'rest') \ .config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \ .config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \ .config('spark.sql.catalog.opencatalog.credential','<client_id>:<client_secret>') \ .config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \ .config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \ .getOrCreate() #Show namespaces spark.sql("show namespaces").show() #Create namespace spark.sql("create namespace spark_demo") #Use namespace spark.sql("use namespace spark_demo") #Show tables; this will show no tables since it is a new namespace spark.sql("show tables").show() #create a test table spark.sql("create table test_table (col1 int) using iceberg"); #insert a record in the table spark.sql("insert into test_table values (1)"); #query the table spark.sql("select * from test_table").show();
詳細情報については、 Sparkでサービス接続を登録するをご参照ください。
パラメーター¶
パラメーター |
説明 |
|---|---|
|
接続先のカタログ名を指定します。 |
|
外部クラウドストレージプロバイダーのMaven座標を指定します:
|
|
サービスプリンシパルが使用するクライアント ID を指定します。 |
|
サービスプリンシパルが使用するクライアントシークレットを指定します。 |
|
Open Catalogアカウントのアカウント識別子を指定します。 |
|
サービスプリンシパルに付与されるプリンシパルロールを指定します。 |
オプション: S3クロスリージョン¶
Open CatalogアカウントがAmazon S3でホストされているが、S3ストレージバケットが配置されているリージョンとは異なるリージョンに配置されている場合、追加のSpark構成設定を提供する必要があります。
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
<target_s3_region> は、S3ストレージバケットがあるリージョンを指定します。リージョンコードのリストについては、 AWS ドキュメントのリージョンエンドポイントをご参照ください。
以下のコード例は、s3リージョンを含むように修正されています。
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('iceberg_lab') \
.config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', 'opencatalog') \
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.opencatalog.type', 'rest') \
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \
.config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \
.config('spark.sql.catalog.opencatalog.credential','<client_id>:<secret>') \
.config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \
.config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
.getOrCreate()
Snowflakeを使用したテーブルのクエリ¶
Snowflakeでカタログ統合オブジェクトを作成し、Snowflakeでオープンカタログのテーブルを表すApache Iceberg™テーブルを作成することができます。次の例では、SnowflakeにIcebergテーブルを作成し、これはSparkによってオープンカタログの内部カタログに作成されたばかりのIcebergテーブルです。
同じSpark接続認証情報を使用することも、新しいSnowflake接続を作成することもできます。新しい接続を作成する場合は、それに応じてロールと権限を設定する必要があります。
カタログ統合オブジェクトの作成:
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_int CATALOG_SOURCE = POLARIS TABLE_FORMAT = ICEBERG CATALOG_NAMESPACE = '<catalog_namespace>' REST_CONFIG = ( CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog' CATALOG_NAME = ‘<catalog_name>’ ) REST_AUTHENTICATION = ( TYPE = OAUTH OAUTH_CLIENT_ID = '<client_id>' OAUTH_CLIENT_SECRET = '<secret>' OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL') ) ENABLED = TRUE; # the <catalog_namespace> created in previous step is spark_demo. # the <catalog_name> created in previous step is demo_catalog.
上記で作成したカタログ統合を使用してSnowflakeでテーブル表現を作成し、テーブルにクエリを実行します。
CREATE OR REPLACE ICEBERG TABLE test_table CATALOG = 'demo_open_catalog_int' EXTERNAL_VOLUME = '<external_volume>' CATALOG_TABLE_NAME = 'test_table'; SELECT * FROM test_table;
ユースケース2: Apache Iceberg™テーブルをSnowflakeからオープンカタログに同期する¶
SnowflakeにIcebergテーブルがある場合、それをオープンカタログに同期することで、他のエンジンがそれらのテーブルをクエリできます。
オープンカタログでの外部カタログの作成¶
SnowflakeのIcebergテーブルは、オープンカタログアカウントの外部カタログで同期できます。
新しいオープンカタログアカウントにサインインします。
新しいカタログを作成するには、左側のペインで カタログ を選択します。
右上の +カタログ を選択します。
カタログを作成 ダイアログで、以下の詳細を入力します。
名前: カタログに demo_catalog_ext という名前を付けます。
外部 のトグルを オン に設定します。
デフォルトのベースロケーション: テーブルデータが保管される場所。
注意
このチュートリアルのユースケース1で作成した内部カタログとは異なるストレージ場所を使用する必要があります。カタログに定義されたアクセス権限が正しく実施されるようにするため、2つの異なるカタログに重複する場所を指定できません。
追加のロケーション(オプション): 複数のストレージ場所をカンマ区切りで指定します。これは主に、このカタログの異なる場所からテーブルをインポートする必要がある場合に使用されます。空白のままにできます。
S3ロール ARN: ストレージ場所への読み書きアクセスを持つ AWS ロール。
外部 ID: (オプション): カタログユーザーとストレージアカウントの信頼関係を作成する際に提供したい秘密。これをスキップすると自動生成されます。このチュートリアルでは、 abc123 のような単純な文字列を使用します。
作成 を選択します。以下の値がカタログに追加されます。
オープンカタログアカウントの IAM ユーザー名。
外部 ID を自分で入力しなかった場合、 外部 ID がカタログ用に自動生成されます。
Snowflakeの新しいサービス接続の構成¶
オープンカタログの左ペインで、 接続 タブを選択し、右上の +接続 を選択します。
サービス接続を構成 ダイアログで、新しいプリンシパルロールを作成するか、利用可能なロールの1つから選択します。
作成 を選択します。
サービス接続を構成 ダイアログから、クライアント ID とクライアントシークレットをテキストエディタにコピーするには、 <CLIENT ID>:<SECRET>として フィールド内で コピー を選択します。
重要
これらのテキスト文字列を後でオープンカタログサービスから取り出すことはできないため、今すぐコピーしておく必要があります。これらのテキスト 文字列は、Sparkを設定する際に使用します。
カタログ権限の設定¶
Snowflake接続が外部カタログに適切な権限を持つよう外部カタログの権限を設定するには、以下の手順に従います。
ナビゲーションペインで、 カタログ を選択し、リストで外部カタログを選択します。
新しいロールを作成するには、 ロール タブを選択します。
+カタログロール を選択します。
カタログロールを作成 ダイアログで、 名前 に spark_catalog_role と入力します。
権限 では、 CATALOG_MANAGE_CONTENT を選択し、 作成 を選択します。
このロールには、テーブルの作成、読み取り、書き込みの権限が与えられます。
プリンシパルロールへに付与 を選択してします。
カタログロールを付与 ダイアログの 付与するプリンシパルロール で my_spark_admin_role を選択します。
付与するカタログロール では、 spark_catalog_role を選択し、 付与 を選択します。
Snowflakeでのカタログ統合オブジェクトの作成¶
Snowflakeで、 CREATE CATALOG INTEGRATION (Snowflake Open Catalog)コマンド を使用して、カタログ統合オブジェクトを作成します。CATALOG_NAME には、Open Catalogアカウントで構成した外部カタログの名前(demo_catalog_ext)を指定します。
Snowflakeは、テーブルとその親名前空間をOpen Catalogのこの外部カタログに同期します。たとえば、Snowflakeに open_catalog_demo.iceberg.test_table_managed Icebergテーブルが登録されていて、カタログ統合で demo_catalog_ext を指定した場合、Snowflakeはそのテーブルを完全修飾名 demo_catalog_ext.open_catalog_demo.iceberg.test_table_managed でOpen Catalogと同期します。
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_ext
CATALOG_SOURCE=POLARIS
TABLE_FORMAT=ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog'
CATALOG_NAME = '<catalog_name>'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<client_id>'
OAUTH_CLIENT_SECRET = '<secret>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED=TRUE;
# the <catalog_name> created in previous step is demo_catalog_ext.
カタログ同期の設定¶
Snowflakeが管理するIcebergテーブルをOpen Catalogに同期する前に、Snowflakeがテーブルを同期するOpen Catalogの外部カタログを指定する必要があります。
カタログ同期を設定するには、 ALTER DATABASE コマンドに CATALOG_SYNC パラメーターを指定します。このパラメーターの値には、Open Catalogのカタログ統合名を指定します。例:
ALTER DATABASE open_catalog_demo SET CATALOG_SYNC = 'demo_open_catalog_ext';
このコードを実行すると、Snowflakeは open_catalog_demo データベース内のすべてのSnowflake管理Icebergテーブルを、 demo_open_catalog_ext カタログ統合で指定したOpen Catalog内の <catalog_name> 外部カタログに同期します。
Snowflake管理Icebergテーブルの作成¶
Snowflake管理のIcebergテーブルを作成し、SnowflakeからOpen Catalogに同期します。詳細については、次をご参照ください。
重要
外部ボリュームの
STORAGE_BASE_URLは、オープンカタログで作成した外部カタログの デフォルトのベースロケーション と一致する必要があります。
use database open_catalog_demo;
use schema iceberg;
# Note that the storage location for this external volume will be different than the storage location for the external volume in use case 1
CREATE OR REPLACE EXTERNAL VOLUME snowflake_demo_ext
STORAGE_LOCATIONS =
(
(
NAME = '<storage_location_name>'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://<s3_location>'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<aws_acct>:role/<rolename>'
STORAGE_AWS_EXTERNAL_ID = '<external_id>'
)
);
CREATE OR REPLACE ICEBERG TABLE test_table_managed (col1 int)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'snowflake_demo_ext'
BASE_LOCATION = 'test_table_managed'
Snowflakeでテーブルを変更すると、変更は自動的にOpen Catalogアカウントの外部カタログと同期されます。Apache Spark™のような他のエンジンは、Open Catalogに接続することでテーブルにクエリできます。
注意
テーブルがオープンカタログとの同期に失敗した場合は、 SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG システム関数を実行して、同期失敗の原因を診断してください。詳細については、SYSTEM$SEND_NOTIFICATIONS_TO_CATALOGをご参照ください。
結論¶
オープンカタログアカウントの内部カタログを使用してテーブルを作成し、クエリを実行し、Apache Spark™またはその他のクエリエンジンを使用してテーブルに対して DML を実行することができます。
Snowflakeでは、オープンカタログのカタログ統合を作成して、以下のタスクを実行できます。
オープンカタログのマネージドテーブルに対してクエリを実行する。
Snowflakeテーブルをオープンカタログアカウントの外部カタログに同期する。
学習した内容¶
オープンカタログアカウントを作成する。
オープンカタログアカウントで内部カタログを作成する。
Sparkを使用して内部カタログにテーブルを作成する。
Snowflakeを使用してオープンカタログのカタログ統合を作成し、オープンカタログアカウントの内部カタログに作成されたテーブルに対してクエリを実行する。
オープンカタログアカウントで外部カタログを作成する。
Snowflakeで管理されたApache Iceberg™テーブルを作成し、2つの親名前空間とともに、Open Catalogアカウントの外部カタログに同期します。チュートリアルでは、データベースレベルでのカタログ同期の設定方法を学びました。ただし、アカウント、スキーマ、またはテーブルレベルで設定し、1つの親名前空間と同期させることもできます。詳細については、次のトピックをご参照ください。
スキーマレベルでのカタログ同期の設定の例については、Snowflakeドキュメントの スキーマレベルでのカタログ同期の設定 をご参照ください。
カタログ同期のセットアップに関する詳細については、Snowflakeドキュメントの CATALOG_SYNCをご参照ください。
テーブルを1つの親名前空間と同期するには、 CREATE DATABASE コマンドで CATALOG_SYNC_NAMESPACE_MODE プロパティを設定します。詳細については、Snowflakeドキュメントの CREATE DATABASE をご参照ください。
注釈
サードパーティのクエリエンジンがカタログの2番目の名前空間レベルまでのテーブルしかクエリできない場合は、テーブルを1つの親名前空間と同期する必要があります。そうしないと、SnowflakeはOpen Catalogの3番目の名前空間レベルにテーブルを同期し、テーブルをクエリできません。