Premiers pas avec Snowflake Open Catalog¶
Vue d’ensemble¶
Snowflake Open Catalog est un catalogue ouvert pour Apache Iceberg™. Open Catalog est disponible en tant que service SaaS géré sur Snowflake. Il est également disponible en tant que code open source que vous pouvez créer et déployer vous-même. Open Catalog fournit une implémentation du catalogue REST Apache Iceberg avec sécurité inter-moteurs via un contrôle d’accès basé sur les rôles.
Dans ce tutoriel, vous apprendrez vos premiers pas avec Open Catalog géré sur Snowflake.
Ce que vous apprendrez¶
Comment créer un nouveau compte Open Catalog.
Comment créer un nouveau catalogue Iceberg dans le compte Open Catalog et le sécuriser à l’aide de RBAC.
Comment utiliser Apache Spark™ pour créer des tables dans le catalogue et exécuter des requêtes.
Comment utiliser Snowflake pour exécuter des requêtes sur les tables du catalogue.
Comment mettre en miroir ou publier des tables Iceberg gérées dans Snowflake vers Open Catalog.
Ce dont vous aurez besoin¶
Privilèges ORGADMIN dans votre organisation Snowflake (pour créer un nouveau compte Open Catalog).
Privilèges ACCOUNTADMIN dans votre compte Snowflake (pour vous connecter au compte Open Catalog). Ce compte Snowflake ne doit pas nécessairement être le même que le compte de l’organisation Snowflake.
Ce que vous ferez¶
Vous effectuerez deux cas d’utilisation :
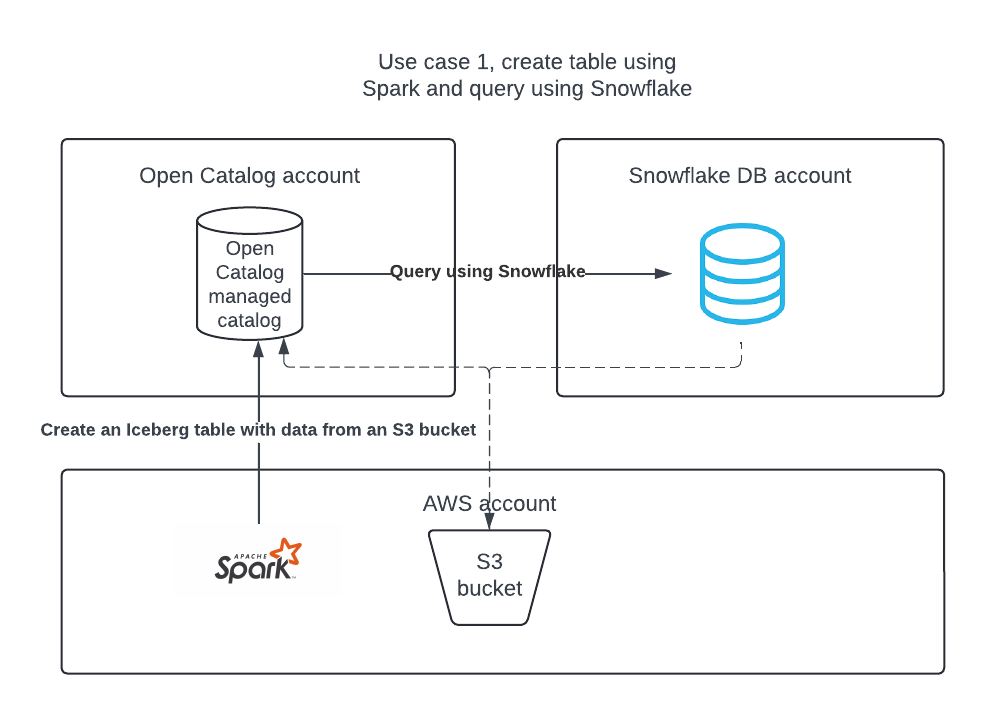
Cas d’utilisation 1 : créer un catalogue dans Open Catalog, créer une table à l’aide d’Apache Spark et interroger la table à l’aide d’Apache Spark et de Snowflake.
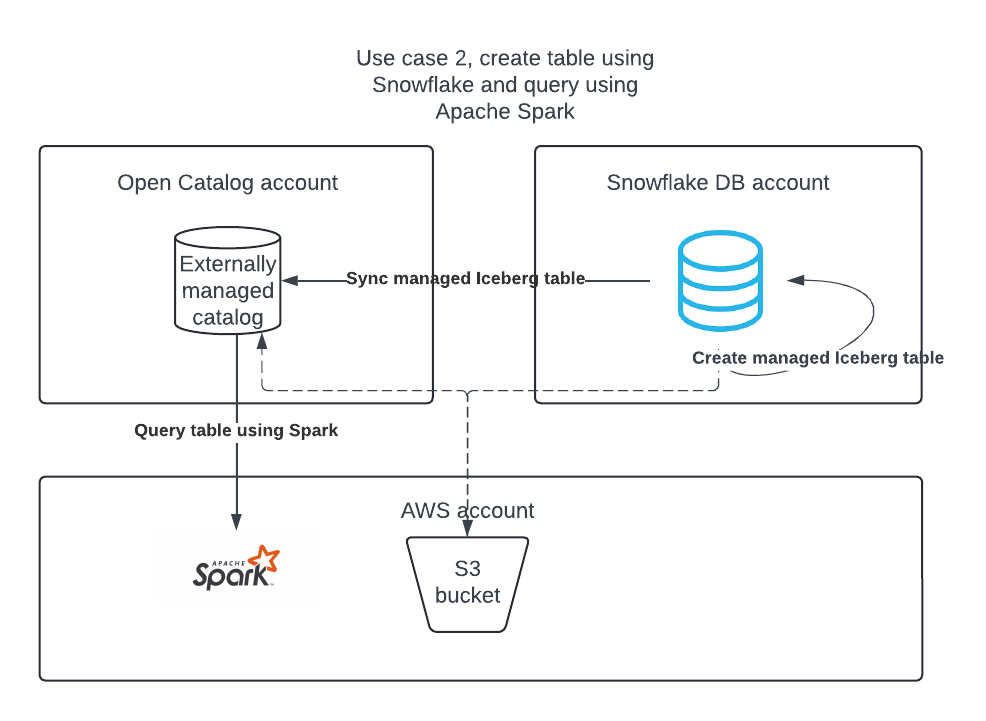
Cas d’utilisation 2 : créer une table Apache Iceberg dans le compte DB de Snowflake à l’aide de Snowflake et la publier dans Open Catalog afin qu’Apache Spark puisse y exécuter des requêtes.
Mise en place de l’environnement¶
Installez Conda, Spark et Jupyter sur votre ordinateur portable.¶
Dans ce tutoriel, vous pouvez utiliser Conda pour créer facilement un environnement de développement et télécharger les paquets nécessaires. Ceci n’est nécessaire que si vous suivez le cas d’utilisation 2 pour utiliser Apache Spark™ pour lire les tables Apache Iceberg™ gérées par Snowflake. Ceci n’est pas nécessaire pour créer ou utiliser des tables Iceberg sur Snowflake.
Pour installer Conda, utilisez les instructions propres à votre OS :
Créer un fichier nommé
environnement.ymlavec le contenu suivant :name: iceberg-lab channels: - conda-forge dependencies: - findspark=2.0.1 - jupyter=1.0.0 - pyspark=3.5.0 - openjdk=11.0.13
Pour créer l’environnement nécessaire, exécutez ce qui suit dans votre shell :
conda env create -f environment.yml
Création d’un compte Open Catalog¶
Un compte Open Catalog peut être créé uniquement par un ORGADMIN.
Dans Snowsight, dans le volet de navigation, sélectionnez Admin> Comptes.
Dans la liste déroulante + Compte, sélectionnez Créer un compte Snowflake Open Catalog.
Renseignez la boîte de dialogue Créer un compte Snowflake Open Catalog :
Cloud : fournisseur Cloud où vous souhaitez stocker les tables Apache Iceberg™.
Région : région dans laquelle vous souhaitez stocker les tables Iceberg.
Édition : édition pour votre compte Open Catalog.
Sélectionnez Suivant.
Dans la boîte de dialogue Créer un nouveau compte, remplissez les champs Nom du compte, Nom d’utilisateur, Mot de passe et E-mail.
Sélectionnez Créer un compte. Votre nouveau compte Open Catalog est créé et une boîte de confirmation apparaît.
Dans la boîte de confirmation, sélectionnez l”URL du localisateur de compte pour ouvrir l’URL du localisateur de compte dans votre navigateur Web.
Ajoutez l’URL du localisateur de compte à vos favoris. Lors de la connexion à Open Catalog, vous devez spécifier l’URL du localisateur de compte.
Connexion à l’interface Web Open Catalog¶
Cliquez sur l’URL du compte que vous avez reçue par e-mail après la création du compte, OR allez sur https://app.snowflake.com.
Cliquez sur Se connecter à un autre compte et connectez-vous avec le compte Open Catalog créé précédemment.
Cas d’utilisation 1 : créer une table à l’aide d’Apache Spark™¶
Créer une politique IAM qui accorde l’accès à votre emplacement S3¶
Si vous n’en avez pas déjà une, commencez par créer une politique IAM qui accorde l’accès à votre emplacement S3. Pour obtenir des instructions sur la création de cette politique, voir Créer une politique IAM qui accorde l’accès à votre emplacement S3.
Création d’un rôle IAM¶
Si vous n’en avez pas déjà un, créez un rôle AWS IAM pour Open Catalog qui accorde des privilèges sur le compartiment S3. Pour obtenir des instructions, voir Créer un rôle IAM. Lorsque les instructions vous invitent à sélectionner une politique, sélectionnez la politique IAM qui accorde l’accès à votre emplacement S3.
Création d’un catalogue interne dans Open Catalog¶
Vous pouvez utiliser un catalogue interne dans votre compte Open Catalog pour créer des tables, les interroger et exécuter des opérations DML dans les tables à l’aide d’Apache Spark™ ou d’autres moteurs de recherche.
Connectez-vous à votre nouveau compte Open Catalog.
Pour créer un nouveau catalogue, dans le volet de gauche, sélectionnez Catalogues.
Sélectionnez + Catalogue en haut à droite.
Dans la boîte de dialogue Créer un catalogue, saisissez les détails suivants :
Nom : nommez le catalogue demo_catalog.
Emplacement de base par défaut : emplacement où les données de la table seront stockées.
Emplacements supplémentaires (facultatif) : liste séparée par des virgules de plusieurs emplacements de stockage. Cette liste est principalement utilisée si vous devez importer des tables à partir de différents emplacements dans ce catalogue. Vous n’êtes pas obligé de la renseigner.
ARN du rôle S3 : rôle AWS qui dispose d’un accès en lecture et écriture aux emplacements de stockage. Saisissez l’ARN du rôle IAM que vous avez créé pour Open Catalog.
**ID externe : (facultatif) : ** secret que vous souhaitez indiquer lors de la création d’une relation de confiance entre l’utilisateur du catalogue et le compte de stockage. Si vous ignorez cette étape, elle sera générée automatiquement. Utilisez une chaîne simple comme abc123 pour ce tutoriel.
Sélectionnez Créer. Votre catalogue est créé et les valeurs suivantes sont ajoutées à votre catalogue :
arn de l’utilisateur IAM pour votre compte Open Catalog.
Si vous n’avez pas saisi d’ID externe, un ID externe est généré automatiquement pour votre catalogue.
Vous aurez besoin de ces valeurs dans la section suivante lorsque vous créerez une relation de confiance.
Création d’une relation de confiance¶
Après avoir créé un catalogue, vous devez configurer une relation de confiance afin que le rôle S3 spécifié dans la configuration ci-dessus puisse lire et écrire des données dans l’emplacement de stockage. Notez que pour réaliser cette tâche, vous aurez besoin de l’arn de l’utilisateur IAM S3 et de l’ID externe pour votre catalogue.
Une fois le catalogue créé, sélectionnez votre catalogue dans la liste pour afficher l’arn de l’utilisateur IAM S3 et l’ID externe pour votre catalogue.
Pour créer la relation de confiance, suivez les instructions de Étape 5 : Accorder à l’utilisateur IAM des autorisations lui permettant d’accéder à des objets de compartiment.
Dans l’objet JSON affiché dans ces instructions :
Pour
<open_catalog_user_arn>, utilisez la valeur sous arn de l’utilisateur IAM dans l’UI d’Open Catalog.Pour
<open_catalog_external_id>, utilisez la valeur sous ID externe dans l’UI d’Open Catalog.

Configurez une nouvelle connexion de service pour Apache Spark™¶
Créez une nouvelle connexion (paire client_id/client_secret) pour qu’Apache Spark exécute des requêtes sur le catalogue que vous venez de créer.
Dans Open Catalog, dans le volet de gauche, sélectionnez l’onglet Connexions, puis sélectionnez + Connexion en haut à droite.
Dans la boîte de dialogue Configurer la connexion de service, créez un nouveau rôle principal ou choisissez l’un des rôles disponibles.
Sélectionnez Créer.
Dans la boîte de dialogue Configurer la connexion de service, pour copier l’ID client et le secret client dans un éditeur de texte, sélectionnez Copier dans le champ En tant que <CLIENT ID>:<SECRET>.
Important
Vous ne pourrez pas récupérer ces chaînes de texte à partir du service Open Catalog ultérieurement, vous devez donc les copier maintenant. Vous utilisez ces chaînes de texte lorsque vous configurez Spark.
Configuration des privilèges du catalogue pour la connexion¶
Vous accordez maintenant des privilèges à la connexion de service afin qu’elle puisse accéder au catalogue. Sans privilèges d’accès, la connexion de service ne peut exécuter aucune requête sur le catalogue.
Dans le volet de navigation, sélectionnez Catalogues, puis sélectionnez votre catalogue dans la liste.
Pour créer un nouveau rôle, sélectionnez l’onglet Rôles.
Sélectionnez + Rôle de catalogue.
Dans la boîte de dialogue Créer un rôle de catalogue, pour Nom, saisissez spark_catalog_role.
Pour Privilèges, sélectionnez CATALOG_MANAGE_CONTENT, puis sélectionnez Créer.
Cette action permet d’attribuer au rôle les privilèges de créer, de lire et d’écrire dans les tables.
Sélectionnez Accorder au rôle principal.
Dans la boîte de dialogue Accorder le rôle de catalogue, pour Rôle principal recevant l’attribution, sélectionnez my_spark_admin_role.
Pour Rôle de catalogue à accorder, sélectionnez spark_catalog_role, puis sélectionnez Accorder.
À la suite de cette procédure, le rôle spark_catalog_role est accordé à my_spark_admin_role, ce qui attribue des privilèges d’administrateur pour la connexion Spark que vous avez créée dans la procédure précédente.
Configuration de Spark¶
Depuis votre terminal, exécutez les commandes suivantes pour activer l’environnement virtuel que vous avez créé lors de la configuration et ouvrez Jupyter Notebooks :
conda activate iceberg-lab
jupyter notebook
Mise en place de Spark¶
Pour enregistrer la connexion au service, exécutez les commandes suivantes dans un carnet Jupyter.
import os os.environ['SPARK_HOME'] = '/Users/<username>/opt/anaconda3/envs/iceberg-lab/lib/python3.12/site-packages/pyspark' import pyspark from pyspark.sql import SparkSession spark = SparkSession.builder.appName('iceberg_lab') \ .config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \ .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \ .config('spark.sql.defaultCatalog', 'opencatalog') \ .config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \ .config('spark.sql.catalog.opencatalog.type', 'rest') \ .config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \ .config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \ .config('spark.sql.catalog.opencatalog.credential','<client_id>:<client_secret>') \ .config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \ .config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \ .getOrCreate() #Show namespaces spark.sql("show namespaces").show() #Create namespace spark.sql("create namespace spark_demo") #Use namespace spark.sql("use namespace spark_demo") #Show tables; this will show no tables since it is a new namespace spark.sql("show tables").show() #create a test table spark.sql("create table test_table (col1 int) using iceberg"); #insert a record in the table spark.sql("insert into test_table values (1)"); #query the table spark.sql("select * from test_table").show();
Pour plus d’informations, consultez Enregistrer une connexion de service dans Spark.
Paramètres¶
Paramètre |
Description |
|---|---|
|
Spécifie le nom du catalogue auquel se connecter. |
|
Spécifie les coordonnées Maven pour votre fournisseur de stockage Cloud externe :
|
|
Spécifie la valeur ID client que le principal de service doit utiliser. |
|
Spécifie le secret client que le principal de service doit utiliser. |
|
Spécifie l’identificateur de compte pour votre compte Open Catalog. |
|
Spécifie le rôle principal attribué au principal de service. |
Facultatif : région transversale S3¶
Lorsque votre compte Open Catalog est hébergé sur Amazon S3 mais qu’il est situé dans une région différente de celle où se trouve votre compartiment de stockage S3, vous devez fournir un paramètre de configuration Spark supplémentaire :
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
<target_s3_region> spécifie la région où se trouve votre compartiment de stockage S3. Pour obtenir la liste des codes de région, voir Points de terminaison régionaux dans la documentation AWS.
L’exemple de code suivant est modifié pour inclure la région s3 :
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('iceberg_lab') \
.config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', 'opencatalog') \
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.opencatalog.type', 'rest') \
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials') \
.config('spark.sql.catalog.opencatalog.uri','https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \
.config('spark.sql.catalog.opencatalog.credential','<client_id>:<secret>') \
.config('spark.sql.catalog.opencatalog.warehouse','<catalog_name>') \
.config('spark.sql.catalog.opencatalog.scope','PRINCIPAL_ROLE:<principal_role_name>') \
.config('spark.sql.catalog.opencatalog.client.region','<target_s3_region>') \
.getOrCreate()
Interrogation de tables à l’aide de Snowflake¶
Vous pouvez créer un objet d’intégration de catalogue dans Snowflake et créer une table Apache Iceberg™ dans Snowflake qui représente la table dans Open Catalog. Dans l’exemple suivant, vous créez une table Iceberg dans Snowflake qui représente la table Iceberg qui vient d’être créée par Spark dans le catalogue interne d’Open Catalog.
Vous pouvez utiliser les mêmes informations d’identification de connexion Spark ou créer une nouvelle connexion Snowflake. Si vous créez une nouvelle connexion, vous devez configurer les rôles et les privilèges en conséquence.
Création d’un objet d’intégration de catalogue :
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_int CATALOG_SOURCE = POLARIS TABLE_FORMAT = ICEBERG CATALOG_NAMESPACE = '<catalog_namespace>' REST_CONFIG = ( CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog' CATALOG_NAME = ‘<catalog_name>’ ) REST_AUTHENTICATION = ( TYPE = OAUTH OAUTH_CLIENT_ID = '<client_id>' OAUTH_CLIENT_SECRET = '<secret>' OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL') ) ENABLED = TRUE; # the <catalog_namespace> created in previous step is spark_demo. # the <catalog_name> created in previous step is demo_catalog.
Créez la représentation de table dans Snowflake à l’aide de l’intégration de catalogue créée ci-dessus et interrogez la table :
CREATE OR REPLACE ICEBERG TABLE test_table CATALOG = 'demo_open_catalog_int' EXTERNAL_VOLUME = '<external_volume>' CATALOG_TABLE_NAME = 'test_table'; SELECT * FROM test_table;
Cas d’utilisation 2 : Synchroniser les tables Apache Iceberg™ de Snowflake avec Open Catalog¶
Si vous avez des tables Iceberg dans Snowflake, vous pouvez les synchroniser avec Open Catalog afin que d’autres moteurs puissent interroger ces tables.
Création d’un catalogue externe dans Open Catalog¶
Les tables Iceberg de Snowflake peuvent être synchronisées dans un catalogue externe dans votre compte Open Catalog.
Connectez-vous à votre nouveau compte Open Catalog.
Pour créer un nouveau catalogue, dans le volet de gauche, sélectionnez Catalogues.
Sélectionnez + Catalogue en haut à droite.
Dans la boîte de dialogue Créer un catalogue, saisissez les détails suivants :
Nom : nommez le catalogue demo_catalog_ext.
Réglez le bouton bascule pour Externe sur Activé.
Emplacement de base par défaut : emplacement où les données de la table seront stockées.
Remarque
Vous devez utiliser un emplacement de stockage différent de celui du catalogue interne que vous avez créé lors du cas d’utilisation 1 de ce tutoriel. Pour garantir que les privilèges d’accès définis pour un catalogue sont appliqués correctement, deux catalogues différents ne peuvent pas avoir d’emplacements qui se chevauchent.
Emplacements supplémentaires (facultatif) : liste séparée par des virgules de plusieurs emplacements de stockage. Cette liste est principalement utilisée si vous devez importer des tables à partir de différents emplacements dans ce catalogue. Vous n’êtes pas obligé de la renseigner.
ARN du rôle S3 : rôle AWS qui dispose d’un accès en lecture et écriture aux emplacements de stockage.
**ID externe : (facultatif) : ** secret que vous souhaitez indiquer lors de la création d’une relation de confiance entre l’utilisateur du catalogue et le compte de stockage. Si vous ignorez cette étape, elle sera générée automatiquement. Utilisez une chaîne simple comme abc123 pour ce tutoriel.
Sélectionnez Créer. Les valeurs suivantes sont ajoutées à votre catalogue :
arn de l’utilisateur IAM pour votre compte Open Catalog.
Si vous n’avez pas saisi d’ID externe, un ID externe est généré automatiquement pour votre catalogue.
Configurez une nouvelle connexion de service pour Snowflake¶
Dans Open Catalog, dans le volet de gauche, sélectionnez l’onglet Connexions, puis sélectionnez + Connexion en haut à droite.
Dans la boîte de dialogue Configurer la connexion de service, créez un nouveau rôle principal ou choisissez l’un des rôles disponibles.
Sélectionnez Créer.
Dans la boîte de dialogue Configurer la connexion de service, pour copier l’ID client et le secret client dans un éditeur de texte, sélectionnez Copier dans le champ En tant que <CLIENT ID>:<SECRET>.
Important
Vous ne pourrez pas récupérer ces chaînes de texte à partir du service Open Catalog ultérieurement, vous devez donc les copier maintenant. Vous utilisez ces chaînes de texte lorsque vous configurez Spark.
Configuration des privilèges du catalogue¶
Pour configurer des privilèges sur le catalogue externe afin que la connexion Snowflake dispose des privilèges appropriés pour un catalogue externe, procédez comme suit :
Dans le volet de navigation, sélectionnez Catalogues, puis sélectionnez votre catalogue externe dans la liste.
Pour créer un nouveau rôle, sélectionnez l’onglet Rôles.
Sélectionnez + Rôle de catalogue.
Dans la boîte de dialogue Créer un rôle de catalogue, pour Nom, saisissez spark_catalog_role.
Pour Privilèges, sélectionnez CATALOG_MANAGE_CONTENT, puis sélectionnez Créer.
Cette action permet d’attribuer au rôle les privilèges de créer, de lire et d’écrire dans les tables.
Sélectionnez Accorder au rôle principal.
Dans la boîte de dialogue Accorder le rôle de catalogue, pour Rôle principal recevant l’attribution, sélectionnez my_spark_admin_role.
Pour Rôle de catalogue à accorder, sélectionnez spark_catalog_role, puis sélectionnez Accorder.
Création d’un objet d’intégration de catalogue dans Snowflake¶
Dans Snowflake, créez un objet d’intégration de catalogue en utilisant la commande CREATE CATALOG INTEGRATION (Snowflake Open Catalog). Pour CATALOG_NAME, indiquez le nom du catalogue externe que vous avez configuré dans votre compte Open Catalog (demo_catalog_ext).
Snowflake synchronise la table ainsi que son espace de noms parent avec ce catalogue externe dans Open Catalog. Par exemple, si vous avez une table Iceberg open_catalog_demo.iceberg.test_table_managed enregistrée dans Snowflake et que vous spécifiez demo_catalog_ext dans l’intégration du catalogue, Snowflake synchronise la table avec Open Catalog avec le nom pleinement qualifié suivant : demo_catalog_ext.open_catalog_demo.iceberg.test_table_managed.
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_ext
CATALOG_SOURCE=POLARIS
TABLE_FORMAT=ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://<orgname>-<my-snowflake-open-catalog-account-name>.snowflakecomputing.com/polaris/api/catalog'
CATALOG_NAME = '<catalog_name>'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<client_id>'
OAUTH_CLIENT_SECRET = '<secret>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED=TRUE;
# the <catalog_name> created in previous step is demo_catalog_ext.
Configurez la synchronisation du catalogue¶
Avant de synchroniser une table Iceberg gérée par Snowflake avec Open Catalog, vous devez spécifier le catalogue externe dans Open Catalog avec lequel Snowflake doit synchroniser la table.
Pour configurer la synchronisation du catalogue, utilisez la commande ALTER DATABASE avec le paramètre CATALOG_SYNC. Pour la valeur de ce paramètre, indiquez le nom de l’intégration du catalogue pour Open Catalog. Par exemple :
ALTER DATABASE open_catalog_demo SET CATALOG_SYNC = 'demo_open_catalog_ext';
Après avoir exécuté ce code, Snowflake synchronise toutes les tables Iceberg gérées par Snowflake dans la base de données open_catalog_demo avec le catalogue externe <catalog_name> dans Open Catalog que vous avez spécifié dans l’intégration du catalogue demo_open_catalog_ext.
Créez une table Iceberg gérée par Snowflake¶
Créez une table Iceberg gérée par Snowflake et synchronisez-la entre Snowflake et Open Catalog. Pour plus d’informations, voir :
Important
L”
STORAGE_BASE_URLpour le volume externe doit correspondre à l”emplacement de base par défaut pour le catalogue externe que vous avez créé dans Open Catalog.
use database open_catalog_demo;
use schema iceberg;
# Note that the storage location for this external volume will be different than the storage location for the external volume in use case 1
CREATE OR REPLACE EXTERNAL VOLUME snowflake_demo_ext
STORAGE_LOCATIONS =
(
(
NAME = '<storage_location_name>'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://<s3_location>'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::<aws_acct>:role/<rolename>'
STORAGE_AWS_EXTERNAL_ID = '<external_id>'
)
);
CREATE OR REPLACE ICEBERG TABLE test_table_managed (col1 int)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'snowflake_demo_ext'
BASE_LOCATION = 'test_table_managed'
Lorsque vous modifiez la table dans Snowflake, les changements sont automatiquement synchronisés avec le catalogue externe dans votre compte Open Catalog. D’autres moteurs tels qu’Apache Spark™ peuvent effectuer des requêtes dans la table en se connectant à Open Catalog.
Remarque
Si la table ne parvient pas à se synchroniser avec Open Catalog, exécutez la fonction système SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG pour diagnostiquer la raison de l’échec de la synchronisation. Pour plus d’informations, voir SYSTEM$SEND_NOTIFICATIONS_TO_CATALOG.
Conclusion¶
Vous pouvez utiliser un catalogue interne dans votre compte Open Catalog pour créer des tables, les interroger et exécuter des opérations DML dans les tables à l’aide d’Apache Spark™ ou d’autres moteurs de recherche.
Dans Snowflake, vous pouvez créer une intégration de catalogue pour Open Catalog afin d’effectuer les tâches suivantes :
Exécuter des requêtes sur les tables gérées par Open Catalog.
Synchroniser les tables Snowflake avec un catalogue externe dans votre compte Open Catalog.
Ce que vous avez appris¶
Créer un compte Open Catalog.
Créer un catalogue interne dans votre compte Open Catalog.
Utiliser Spark pour créer des tables sur le catalogue interne.
Utiliser Snowflake pour créer une intégration de catalogue pour Open Catalog afin d’exécuter des requêtes sur une table créée sur un catalogue interne dans votre compte Open Catalog.
Créer un catalogue externe dans votre compte Open Catalog.
Créez une table Apache Iceberg&trade ; gérée dans Snowflake et synchronisez-la, ainsi que deux espaces de noms parents, avec le catalogue externe de votre compte Open Catalog. Dans le tutoriel, vous avez appris à configurer la synchronisation du catalogue au niveau de la base de données. Toutefois, vous pouvez également le paramétrer au niveau du compte, du schéma ou de la table, et le synchroniser avec un espace de noms parent. Pour plus d’informations, consultez les rubriques suivantes :
Pour un exemple de paramétrage de la synchronisation du catalogue au niveau du schéma, voir Paramétrer la synchronisation du catalogue au niveau du schéma dans la documentation de Snowflake.
Pour plus d’informations sur la configuration de la synchronisation des catalogues, voir CATALOG_SYNC dans la documentation de Snowflake.
Pour synchroniser la table avec un espace de noms parent, définissez la propriété CATALOG_SYNC_NAMESPACE_MODE à l’aide de la commande CREATE DATABASE. Pour en savoir plus, consultez la section CREATE DATABASE dans la documentation de Snowflake.
Note
Si votre moteur de requête tiers ne peut interroger que des tables situées jusqu’au deuxième niveau d’espace de noms dans un catalogue, vous devez synchroniser la table avec un espace de noms parent. Sinon, Snowflake synchronisera la table au troisième niveau de l’espace de noms dans Open Catalog et vous ne pourrez pas effectuer de requête sur la table.